

ランダムフォレストによる予測モデル作成 / Modeler
ランダムフォレストの概要
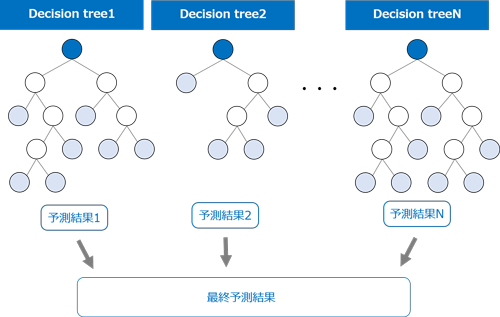
ランダムフォレスト(Random forest)は、ディシジョンツリー(Decision tree;決定木)に基づいた機械学習の代表的な手法です。重複を許すランダムサンプリングによって多数のディシジョンツリーを作成し、各ツリーの予測結果の多数決をとることで最終予測値を決定します。
大きな特徴として、レコードだけではなく特徴量(入力フィールド)もサンプリングされるため、候補となる特徴量が非常に多いデータセットでも比較的高速にツリーが作成され、各ツリーの多様性と高い予測精度が期待できます。複数のツリーをランダムに構築して、それらの結果を組み合わせるので、集団学習やアンサンブル学習とも呼ばれます。
 (2)「作成オプション」タブ >「基本」項目を開きます。
(3)「作成するツリーの数」を[50]、「最大の深さの指定」を[50]、「リーフノードの最小サイズ」を「5」と設定します。
(2)「作成オプション」タブ >「基本」項目を開きます。
(3)「作成するツリーの数」を[50]、「最大の深さの指定」を[50]、「リーフノードの最小サイズ」を「5」と設定します。
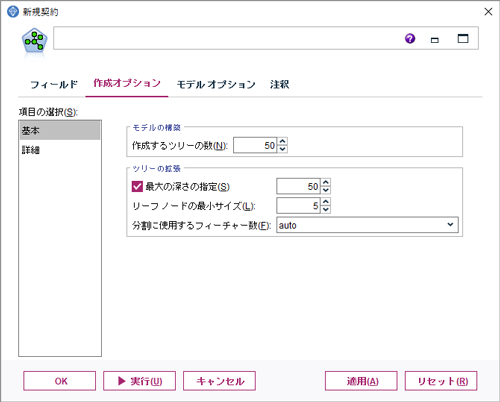 「作成するツリーの数」:作成するツリー数を指定するこができます。構築するモデル数が多くなる分モデルの精度が向上しますが、処理に時間がかかります。デフォルトは10と設定されています。この例では、50に増やしてみます。
「最大の深さの指定」:ツリーの最大の深さを設定します。選択されていない場合、リーフがすべて純粋なリーフになるか、または、すべてのリーフがノードの最小サイズになるまで展開されます。
「リーフノードの最小サイズ」:分割されたリーフノードに最低限含まれていなければならないレコード数を指定します。
「分割に使用するフィーチャー数」:ツリーの分岐に使用される特徴量(入力フィールド)の数を指定します。これは、ランダムにサンプリングされるフィールドの数を意味します。全フィールド数をMとするとき、以下の方法から選択できます。一般的にフィールド数Mの平方根(√M)が推奨されています。
auto :分類木は√M、回帰木はM
sqrt :√M
log2 :log2(M)
(4)「詳細」項目を開きます。
(5)「ツリーの作成時にブートストラップサンプルを使用」、「一般化の精度を推定するためにOut of Bagサンプルを使用」、「結果を再現」にチェックを入れます。
「作成するツリーの数」:作成するツリー数を指定するこができます。構築するモデル数が多くなる分モデルの精度が向上しますが、処理に時間がかかります。デフォルトは10と設定されています。この例では、50に増やしてみます。
「最大の深さの指定」:ツリーの最大の深さを設定します。選択されていない場合、リーフがすべて純粋なリーフになるか、または、すべてのリーフがノードの最小サイズになるまで展開されます。
「リーフノードの最小サイズ」:分割されたリーフノードに最低限含まれていなければならないレコード数を指定します。
「分割に使用するフィーチャー数」:ツリーの分岐に使用される特徴量(入力フィールド)の数を指定します。これは、ランダムにサンプリングされるフィールドの数を意味します。全フィールド数をMとするとき、以下の方法から選択できます。一般的にフィールド数Mの平方根(√M)が推奨されています。
auto :分類木は√M、回帰木はM
sqrt :√M
log2 :log2(M)
(4)「詳細」項目を開きます。
(5)「ツリーの作成時にブートストラップサンプルを使用」、「一般化の精度を推定するためにOut of Bagサンプルを使用」、「結果を再現」にチェックを入れます。
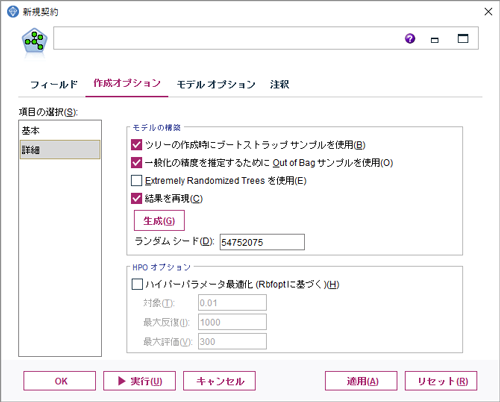 「ツリーの作成時にブートストラップサンプルを使用」:ブートストラップサンプルを使用したモデルが作成されます。
「一般化の精度を推定するためにOut of Bagサンプルを使用」:OOBサンプル(ブートストラップサンプリングで選ばれなかったサンプル)で一般化精度をテストします。
「結果を再現」:ランダムサンプリングを行う際のシードの指定を行うことができます。この設定によって、同じモデルを再現することができます。デフォルトでは無効になっているため、ランダムサンプリングの結果に影響があり、モデル作成を行うたびに異なる結果が得られることになります。
(6)「ランダムフォレスト」ノードの「実行」ボタンをクリックします。
「ツリーの作成時にブートストラップサンプルを使用」:ブートストラップサンプルを使用したモデルが作成されます。
「一般化の精度を推定するためにOut of Bagサンプルを使用」:OOBサンプル(ブートストラップサンプリングで選ばれなかったサンプル)で一般化精度をテストします。
「結果を再現」:ランダムサンプリングを行う際のシードの指定を行うことができます。この設定によって、同じモデルを再現することができます。デフォルトでは無効になっているため、ランダムサンプリングの結果に影響があり、モデル作成を行うたびに異なる結果が得られることになります。
(6)「ランダムフォレスト」ノードの「実行」ボタンをクリックします。
 モデル作成が完了すると、モデルナゲットが生成されます。指定したツリーの数やレコード数、PCのスペック等の環境によって、作成するまでに時間がかかる場合があります。
【結果の確認】
生成されたモデルナゲットに結果の詳細が表示されます。
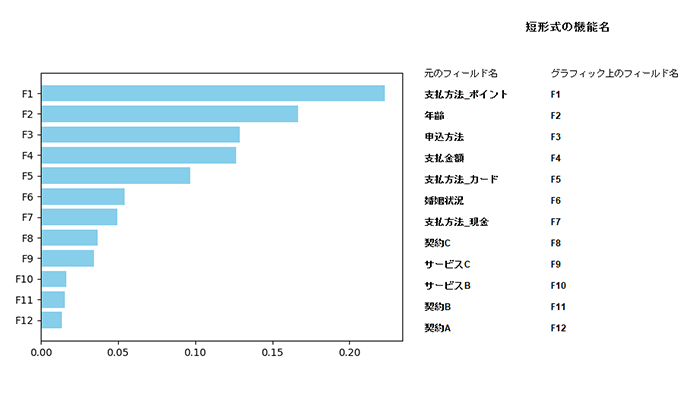
予測変数の重要度では、入力フィールド(特徴量)の重要度を確認することができます。「支払方法_ポイント」、「年齢」、「申込方法」、「支払金額」の順に重要であることがわかります。
モデル作成が完了すると、モデルナゲットが生成されます。指定したツリーの数やレコード数、PCのスペック等の環境によって、作成するまでに時間がかかる場合があります。
【結果の確認】
生成されたモデルナゲットに結果の詳細が表示されます。
予測変数の重要度では、入力フィールド(特徴量)の重要度を確認することができます。「支払方法_ポイント」、「年齢」、「申込方法」、「支払金額」の順に重要であることがわかります。
 ランダムフォレストは、多数のツリー(この例では50個)を生成するため、ツリー図は出力されません。
(7)「精度分析」ノードをリンクして実行します。
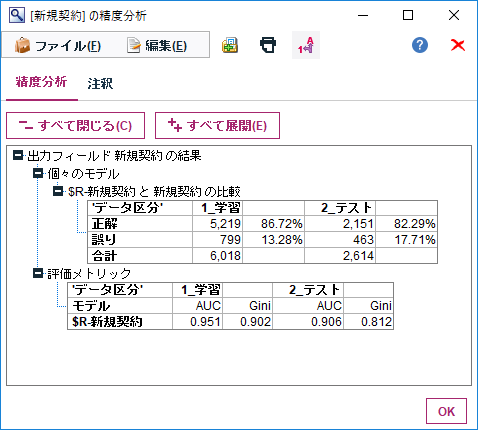
精度分析ノードを実行して学習データとテストデータの正解率を確認します。どちらも正解率80%以上で、AUCも0.9超えており精度も高く、オーバーフィットの心配も問題なさそうです。
ランダムフォレストは、多数のツリー(この例では50個)を生成するため、ツリー図は出力されません。
(7)「精度分析」ノードをリンクして実行します。
精度分析ノードを実行して学習データとテストデータの正解率を確認します。どちらも正解率80%以上で、AUCも0.9超えており精度も高く、オーバーフィットの心配も問題なさそうです。
 このようにランダムフォレストは、単純なディシジョンツリーの手法と比べて比較的高い予測精度が期待でき、過学習の問題も起きにくいメリットがあります。特に、特徴量(入力フィールド)の候補が大量にあるデータセットでは、重要度の評価もしやすく便利です。ただし、サンプリングとモデル作成を大量に行うことになりますので、モデル作成やスコアリングの時間が多くかかります。
また、はじめから特徴量の候補が少ない場合などは、サンプリングによってかえって精度が低くなる場合もあります。分析の目的や使用するデータセット、分析環境などの条件によっては、ディシジョンツリーや線型モデルなどのよりシンプルな手法で事足りることもあり、状況に応じた手法選択が必要になるでしょう。
目的や使い方、用途に応じて、IBM SPSS製品を有効にご活用いただき、課題解決・価値創造にお役立てください。
このようにランダムフォレストは、単純なディシジョンツリーの手法と比べて比較的高い予測精度が期待でき、過学習の問題も起きにくいメリットがあります。特に、特徴量(入力フィールド)の候補が大量にあるデータセットでは、重要度の評価もしやすく便利です。ただし、サンプリングとモデル作成を大量に行うことになりますので、モデル作成やスコアリングの時間が多くかかります。
また、はじめから特徴量の候補が少ない場合などは、サンプリングによってかえって精度が低くなる場合もあります。分析の目的や使用するデータセット、分析環境などの条件によっては、ディシジョンツリーや線型モデルなどのよりシンプルな手法で事足りることもあり、状況に応じた手法選択が必要になるでしょう。
目的や使い方、用途に応じて、IBM SPSS製品を有効にご活用いただき、課題解決・価値創造にお役立てください。
IBM SPSS Modeler で行うランダムフォレスト
IBM SPSS Modelerでは、ランダムフォレストによるモデル作成のための機能が「Random Trees」ノードと「ランダムフォレスト」ノードとして用意されています。ランダムフォレストノードはPythonのパッケージを利用しており、GUIで簡単に実行することができます。この例では、ランダムフォレストノードによる予測モデル作成の手順を確認します。 ■ 必要なソフトウェア ・IBM SPSS Modeler (Ver18.2 以上) ・Essentials for Python ※IBM SPSS Modeler本体のインストール時に自動的にインストールされます。 ■Modelerで使用できるノード Pythonで実装されるランダムフォレストです。 分類木はGini(ジニ)係数、回帰木はMSE(平均二乗誤差)に基づいて分割されます。
ランダムフォレストの手順
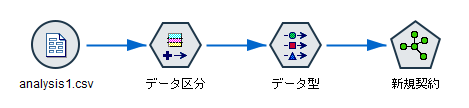
(1) 「モデル作成」パレットの「ランダムフォレスト」ノードをストリームに追加して開きます。 モデル作成の目的フィールド(対象)と特徴量(入力)の候補は、データ型ノードで指定しておきます。 この例では、顧客の新規契約(あり/なし)を、顧客の年齢や婚姻状況をはじめとする属性やサービスの利用状況などの行動履歴から予測するモデル作成を行います。
(2)「作成オプション」タブ >「基本」項目を開きます。
(3)「作成するツリーの数」を[50]、「最大の深さの指定」を[50]、「リーフノードの最小サイズ」を「5」と設定します。
「作成するツリーの数」:作成するツリー数を指定するこができます。構築するモデル数が多くなる分モデルの精度が向上しますが、処理に時間がかかります。デフォルトは10と設定されています。この例では、50に増やしてみます。
「最大の深さの指定」:ツリーの最大の深さを設定します。選択されていない場合、リーフがすべて純粋なリーフになるか、または、すべてのリーフがノードの最小サイズになるまで展開されます。
「リーフノードの最小サイズ」:分割されたリーフノードに最低限含まれていなければならないレコード数を指定します。
「分割に使用するフィーチャー数」:ツリーの分岐に使用される特徴量(入力フィールド)の数を指定します。これは、ランダムにサンプリングされるフィールドの数を意味します。全フィールド数をMとするとき、以下の方法から選択できます。一般的にフィールド数Mの平方根(√M)が推奨されています。
auto :分類木は√M、回帰木はM
sqrt :√M
log2 :log2(M)
(4)「詳細」項目を開きます。
(5)「ツリーの作成時にブートストラップサンプルを使用」、「一般化の精度を推定するためにOut of Bagサンプルを使用」、「結果を再現」にチェックを入れます。
「ツリーの作成時にブートストラップサンプルを使用」:ブートストラップサンプルを使用したモデルが作成されます。
「一般化の精度を推定するためにOut of Bagサンプルを使用」:OOBサンプル(ブートストラップサンプリングで選ばれなかったサンプル)で一般化精度をテストします。
「結果を再現」:ランダムサンプリングを行う際のシードの指定を行うことができます。この設定によって、同じモデルを再現することができます。デフォルトでは無効になっているため、ランダムサンプリングの結果に影響があり、モデル作成を行うたびに異なる結果が得られることになります。
(6)「ランダムフォレスト」ノードの「実行」ボタンをクリックします。
モデル作成が完了すると、モデルナゲットが生成されます。指定したツリーの数やレコード数、PCのスペック等の環境によって、作成するまでに時間がかかる場合があります。
【結果の確認】
生成されたモデルナゲットに結果の詳細が表示されます。
予測変数の重要度では、入力フィールド(特徴量)の重要度を確認することができます。「支払方法_ポイント」、「年齢」、「申込方法」、「支払金額」の順に重要であることがわかります。
ランダムフォレストは、多数のツリー(この例では50個)を生成するため、ツリー図は出力されません。
(7)「精度分析」ノードをリンクして実行します。
精度分析ノードを実行して学習データとテストデータの正解率を確認します。どちらも正解率80%以上で、AUCも0.9超えており精度も高く、オーバーフィットの心配も問題なさそうです。
このようにランダムフォレストは、単純なディシジョンツリーの手法と比べて比較的高い予測精度が期待でき、過学習の問題も起きにくいメリットがあります。特に、特徴量(入力フィールド)の候補が大量にあるデータセットでは、重要度の評価もしやすく便利です。ただし、サンプリングとモデル作成を大量に行うことになりますので、モデル作成やスコアリングの時間が多くかかります。
また、はじめから特徴量の候補が少ない場合などは、サンプリングによってかえって精度が低くなる場合もあります。分析の目的や使用するデータセット、分析環境などの条件によっては、ディシジョンツリーや線型モデルなどのよりシンプルな手法で事足りることもあり、状況に応じた手法選択が必要になるでしょう。
目的や使い方、用途に応じて、IBM SPSS製品を有効にご活用いただき、課題解決・価値創造にお役立てください。
■ 参考文献 [1] LEO BREIMAN『Random Forests』Machine Learning, 45(1), 5-32, 2001.(Jan., 2001) [2] P. Geurts, D. Ernst., and L. Wehenkel『Extremely randomized trees』Machine Learning, 63(1), 3-42, 2006. [3]Trevor Hastie(著),Robert Tibshirani(著),Jerome Friedman(著)杉山将(監訳)他『統計的学習の基礎-データマイニング・推論・予測-』