

ファイルの結合-変数の追加(3)V24以前の手順 / Statistics
IBM SPSS Statisticsによる変数の追加の手順は以下の通りです。この手順は、V24に基づいています。V25では、設定方法の考え方は同じですがインターフェイスがやや異なるため「ファイルの結合-変数の追加(2)V25の手順 / Statistics」をご確認ください。
■ 必要なソフトウェア ・IBM SPSS Statistics Base V22~v24
変数の追加を行うためには、事前に結合に使用するデータファイルを開いておいた方が良いでしょう。必須の作業ではありませんが、データセット名を変更しておくと作業内容がより分かりやすくなります(デフォルトのデータセット名は、データファイルを開いた順番にデータセット1、データセット2のように定義されます)。データセット名の変更は、「ファイル」>「データセット名の変更」メニューを使用します。ここでは、以下の2つのファイルの変数を統合します。
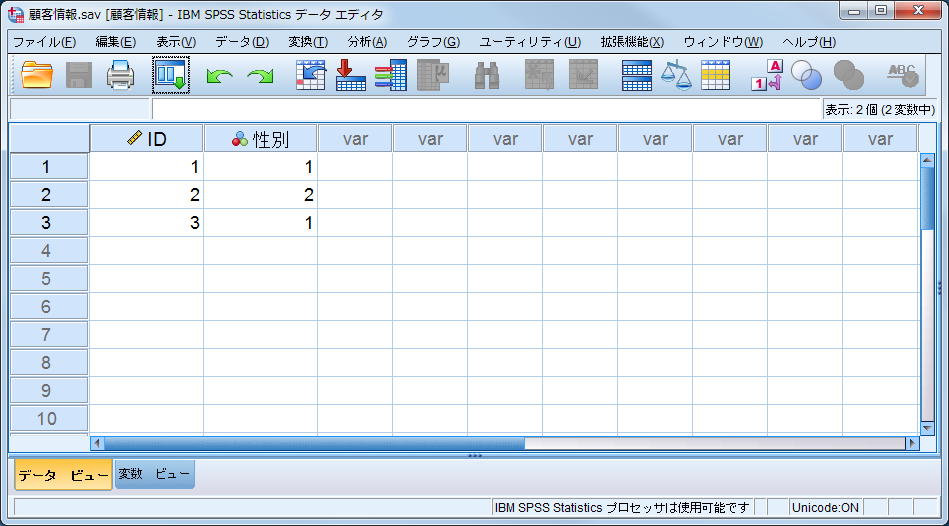
■ 顧客情報を含むデータセット(※データセット名を「顧客情報」に変更済み) 顧客情報として「ID」「性別」の2つの変数を含みます。「ID」に重複はありません。
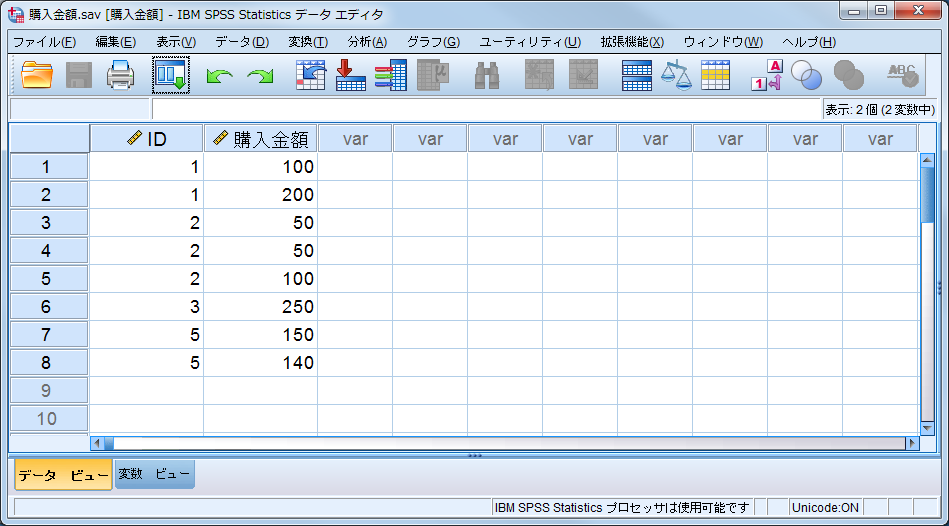
■ 購買情報を含むデータセット(※データセット名を「購入金額」に変更済み) 購買情報として「ID」「購入金額」の2つの変数を含みます。「ID」に重複があります。
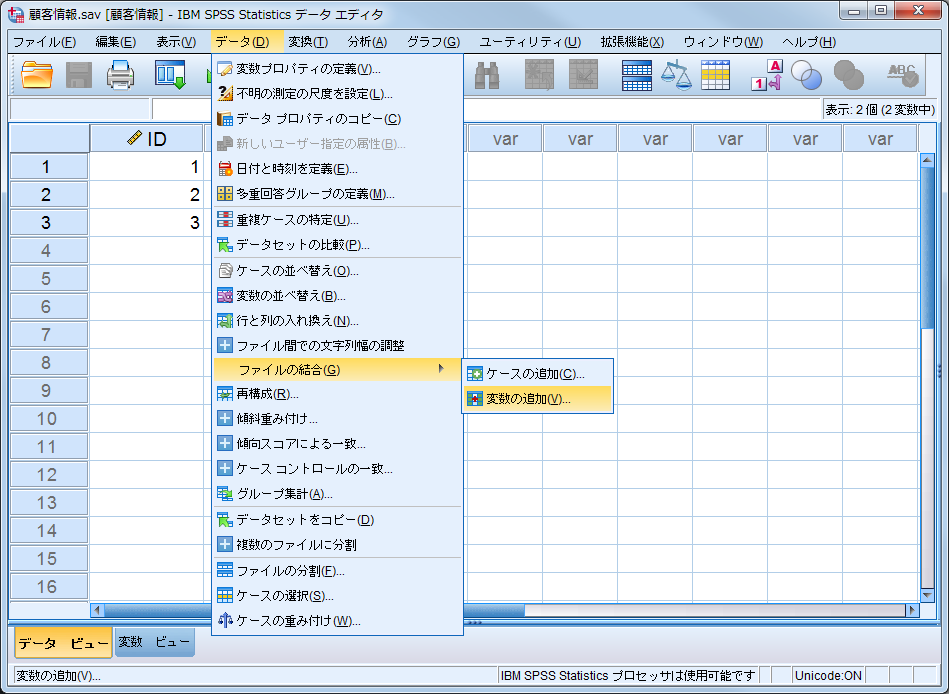
■ 変数の追加の手順 あらかじめ[顧客情報]と[購入金額]の2つのデータファイルを読み込んでおき、[顧客情報]データセットをアクティブにしてファイル結合を行います。なお、IBM SPSS Statistics形式のデータファイルの場合は、あらかじめファイルを開く必要はありませんが、ExcelやCSVなどの別の形式のデータファイルの場合は、一度SPSSに読み込んでおかなければなりません。また、結合のキーとなる「ID」はあらかじめ昇順に並び替え(ソート)されている必要があります。ケースの並び替え(ソート)を行うためには、データビューでキー変数名「ID」を右クリックして「昇順で並び替え」を選択します。
(1) [データ] メニュー > [ファイルの結合] > [変数の結合] を選択します。
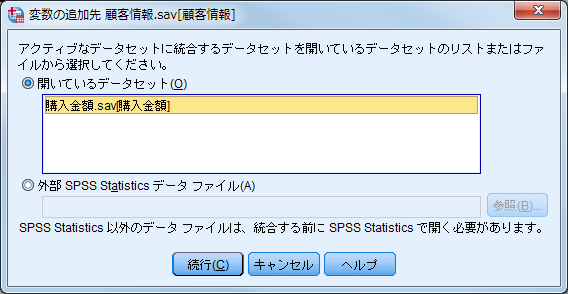
(2)「変数の追加先ダイアログボックス」で、必要な設定を行います。 開いているデータセットの一覧から[購入金額]を選択して「続行」ボタンをクリックします。
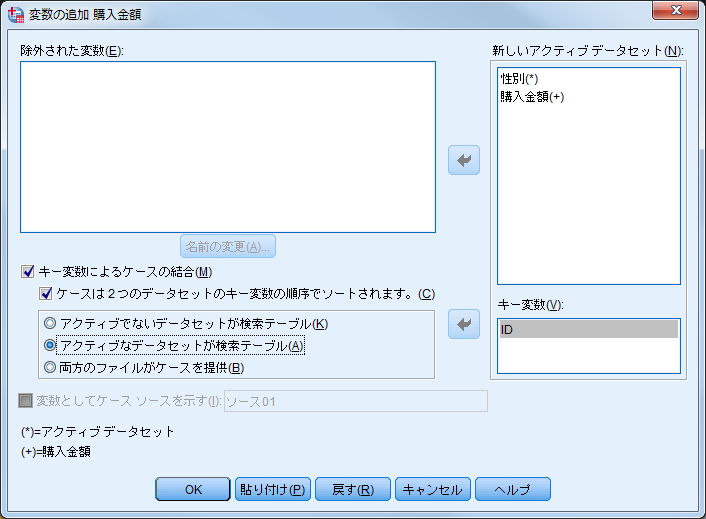
(3)表示される「変数の追加」ダイアログボックスで必要な設定を行います。
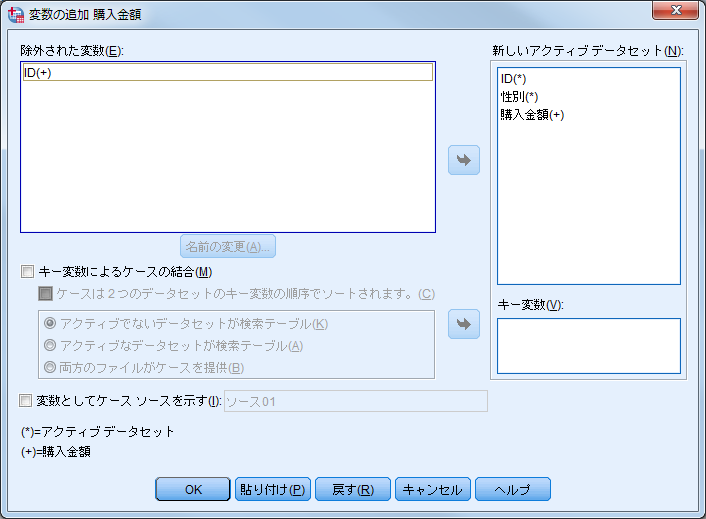
「新しいアクティブデータセット」には、結合後のファイルに含まれる変数が表示されています。変数名の後ろについている記号(*)はその変数がアクティブデータセット(この例では[顧客情報])、(+)はその変数が追加されるデータセット(この例では[購入金額])から得られることを意味します。1つのファイルで同じ変数名を使うことは許されないため、名前が重複している変数は「除外された変数」にリストされます。変数を除外せずに結合後のデータファイルに含めたい場合は「名前の変更」を行います。ただし、キー変数は名前を一致させておく必要があります。
(4)「キー変数によるケースの結合」にチェックを入れます。 (5)「キー変数」に「ID」を移動します。 (6)「ケースは2つのデータセットのキー変数の順序でソートされます」にチェックを入れます。
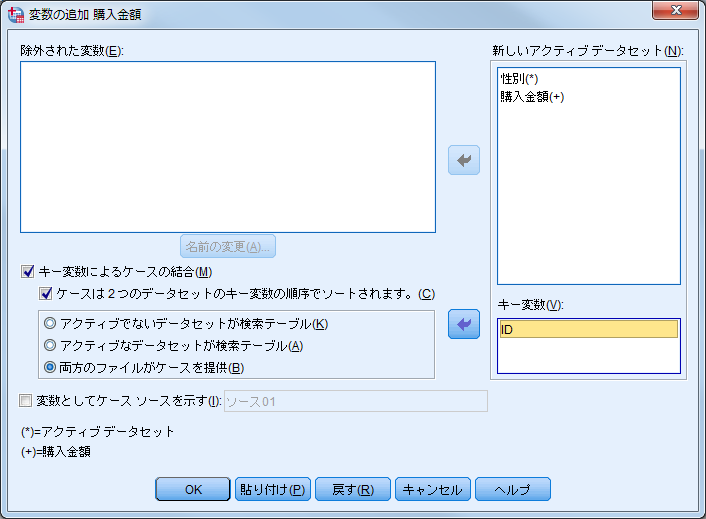
「キー変数によるケースの結合」にチェックを入れることで、IDなどのキー変数の値の一致を条件に変数を統合することができます。チェックを入れない場合は、結合の際にキー変数を使用せず、ファイルの並び順のまま2つのファイルのケース同士を1:1の関係で結合されることになります。この方法は、ケースの並び順がずれている場合などに間違ったケース同士が結合されてしまう危険性があるため、キー変数を用いた結合が推奨されます。次に、2つのデータセットのキー変数の値の関係性を「N:1」「1:N」「1:1」の中から指定します。
■ 「アクティブでないデータセットが検索テーブル」(N:1の結合) キー変数の値の一致を条件に、2つのファイルをN:1の関係で結合します。多:1の結合とも呼ばれます。この方法は、アクティブなデータセットのキーが重複していて、もう一方のファイルのキー値が一意(ユニーク)であることを前提としています。キー値が一意(ユニーク)なファイルが検索テーブルに該当します。この例では、アクティブなデータセットが検索テーブルになりますので、この選択肢を使用することはできません。
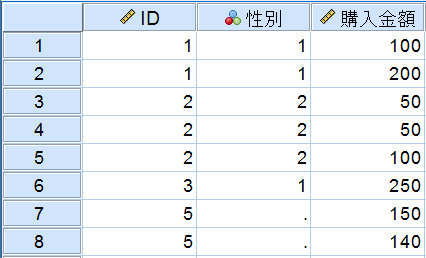
■ 「アクティブなデータセットが検索テーブル」(1:Nの結合) キー変数の値の一致を条件に、2つのファイルを1:Nの関係で結合します。1:多の結合とも呼ばれます。この方法は、アクティブなデータセットのキー値が一意(ユニーク)で、もう一方のファイルのキー値が重複することを前提としています。この例では、アクティブなデータセットが検索テーブルになり、実際にファイル結合を実施すると以下のような結果が得られます。顧客情報と購入金額2つのデータセットのIDの値が、1:Nの関係で結合されており、IDが重複しているケースが有効値になります。なお、この方法の場合のシンタックスコードは「MATCH FILES /TABLE=*」のように「/TABLE」が指定されます。
■ 「両方のファイルがケースを提供」 キー変数の値の一致を条件に、2つのファイルを1:1の関係で結合します。この方法では、互いのファイルのキー値は1回しか使用されず、重複したキー値は無視されます。もしこの例で「両方のファイルがケースを提供」によって結合するとその結果は以下のようになり、顧客情報と購入金額2つのデータセットのIDの値が、1:1の関係で結合され、IDが重複している場合のケースは欠損値になります。なお、この方法の場合のシンタックスコードは「MATCH FILES /FILE=*」のように「/FILE」が指定されます。
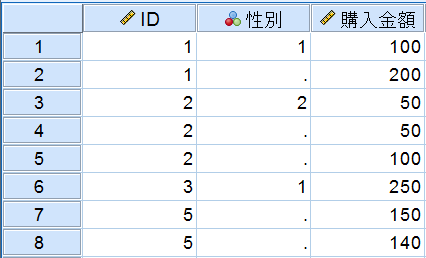
「両方のファイルがケースを提供」を指定した場合は、2つのデータセットのキー変数がそれぞれ一意(ユニーク)な値を持つことを前提とするため、値が重複する場合でも1:1の関係で結合が行われ、重複しているキー値のケースは欠損値になります。1:1の関係になっていないデータセットでも結合が行われるため、出力ビューアには以下のような警告のメッセージが表示されます。

(7) 「アクティブなデータセットが検索テーブル」を選択します。
(8) OKボタンをクリックします。
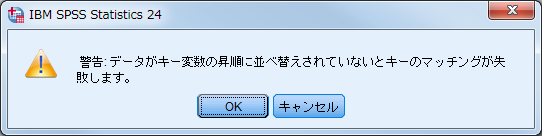
変数の追加を行うためには、キー変数の値が昇順に並んでいる必要があるため、実行前に確認のためのメッセージボックスが表示されます。
(9) OKボタンをクリックします。
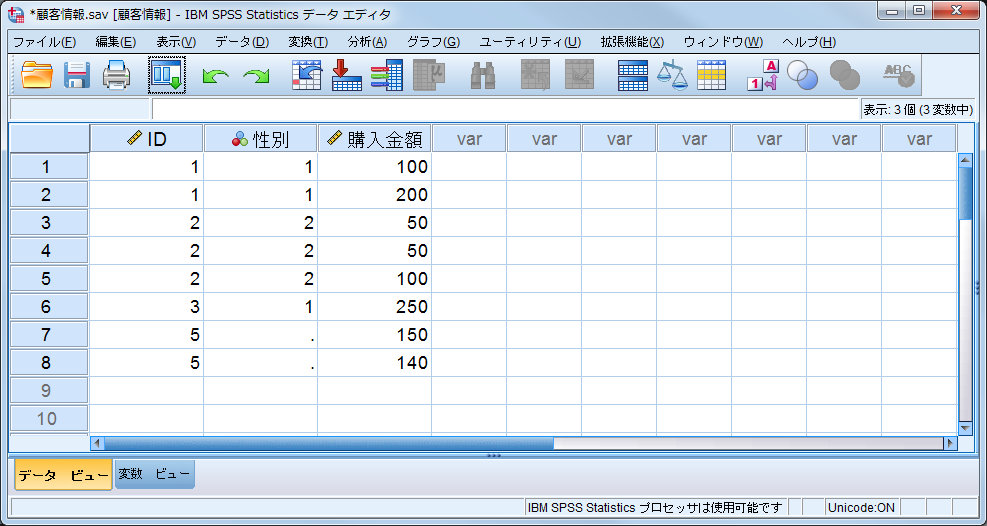
[顧客情報]と[購入金額]の2つのデータセットが結合されて「ID」「性別」「購入金額」の全ての変数が使用できるようになりました。顧客情報に含まれていないID=5のケースは「性別」の値がありませんので欠損値になっています(欠損値のケースを除外したい場合は、ケースの選択メニューを使用します)。
このように、ファイルの結合を行うことによって、異なるデータファイルに含まれる変数を統合して、分析や集計に使用することができるようになります。なお、ファイルの結合のメニューで同時に扱うことができるのは2つのファイルまでです。3つ以上のファイルを結合させる場合は、メニューを使用して順繰りに結合作業を繰り返すか、シンタックスコマンド「MATCH FILE」または「STAR JOIN」を使用します。シンタックスの詳細については「IBM_SPSS_Statistics_Command_Syntax_Reference.pdf」またはシンタックスヘルプをご確認ください。
目的や使い方、用途に応じて、IBM SPSS製品を有効にご活用いただき、課題解決・価値創造にお役立てください。
■ E-Learningコース:IBM SPSS Statisticsによる統計解析【入門編B】データの加工と前処理 SPSSによる統計解析を学習するための ハンズオン形式のE-Learningコース(Textbook付属) ※本コースはV25に基づいています。 https://www.stats-guild.com/spss-e-learning-textbook
■ IBM SPSS Statistics Base IBM SPSS Statisticsによるデータ入力、読込み、データ加工、基本統計量の出力、推測統計(仮説検定・信頼区間)、回帰分析、因子分析、クラスター分析、分散分析、グラフ作成、外部ファイルへのエクスポート、拡張機能などを有する基本モジュール https://www.stats-guild.com/ibm-spss