

複数の従属変数を持つ横持ちデータの再構成
1回目・2回目・3回目の得点や測定値などを分析する経時的なデータの入力方法として、縦持ち(ケースグループ/ロング形式)と横持ち(変数グループ/ワイド形式)の区別を考える場合があります。縦持ちの場合は、独立したサンプルのt検定、1元配置分散分析、2元配置分散分析、線型モデル、一般化線型モデル、混合効果モデルなどの手法が対象になります。一方、横持ちの場合は、対応のあるt検定、反復測定分散分析などの手法が対象になります。
どちらの入力方法をとるかは、適用する分析手法に合わせることになりますが、データの持ち方を後から変更したい場合に役立つのが、IBM SPSS Statistics Baseの機能として用意されている「データの再構成」です。この機能は、横持ち→縦持ち、縦持ち→横持ち、行列の入れ替えに対応できるデータ加工の機能です。
■ 縦持ち形式(ケースグループ/ロング形式)のデータファイルの例:(ケース数=30)
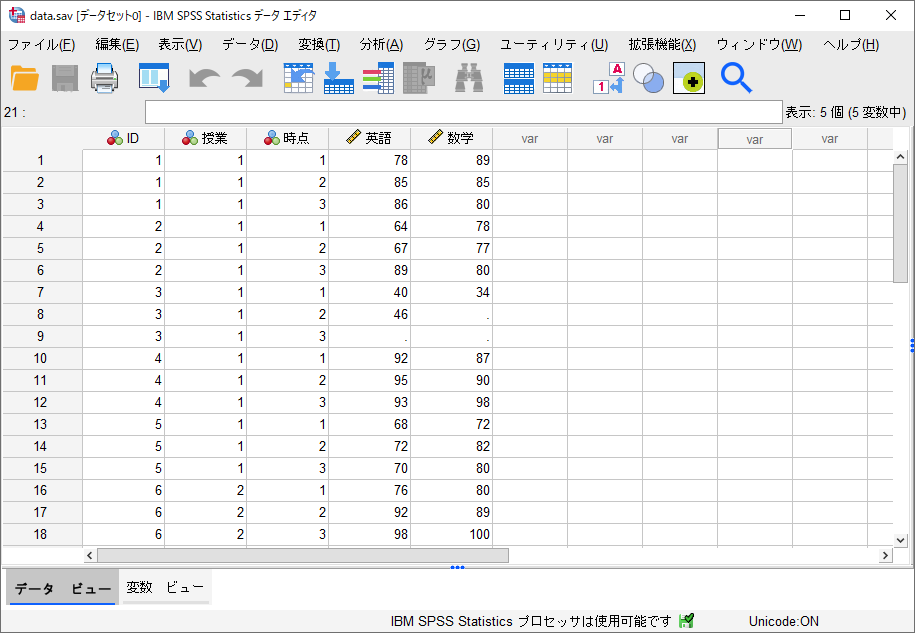 上記のデータファイルは、縦持ち形式の例として、「ID」、「授業」(1:従来の授業法、2:新しい授業法)、「時点(1:1回目、2:2回目、3:3回目)」、「英語」の得点、「数学」の得点の5個の変数を含んでいます。IDの値に重複があり(1人が複数行にまたがって入力されており)、1人の3回分のテスト結果が縦に入力されていることが分かります。横持ち形式との大きな違いとして、1回目~3回目のテストを区別する変数として「時点」を持ちます。このデータファイルのケース数は30(n=30)で、10人分の合計3回のテスト結果のデータを記録しています。
この内容と全く同じデータを、以下のように横持ち形式で入力することもできます。
■ 横持ち形式(変数グループ/ワイド形式)のデータファイルの例:(ケース数=10)
上記のデータファイルは、縦持ち形式の例として、「ID」、「授業」(1:従来の授業法、2:新しい授業法)、「時点(1:1回目、2:2回目、3:3回目)」、「英語」の得点、「数学」の得点の5個の変数を含んでいます。IDの値に重複があり(1人が複数行にまたがって入力されており)、1人の3回分のテスト結果が縦に入力されていることが分かります。横持ち形式との大きな違いとして、1回目~3回目のテストを区別する変数として「時点」を持ちます。このデータファイルのケース数は30(n=30)で、10人分の合計3回のテスト結果のデータを記録しています。
この内容と全く同じデータを、以下のように横持ち形式で入力することもできます。
■ 横持ち形式(変数グループ/ワイド形式)のデータファイルの例:(ケース数=10)
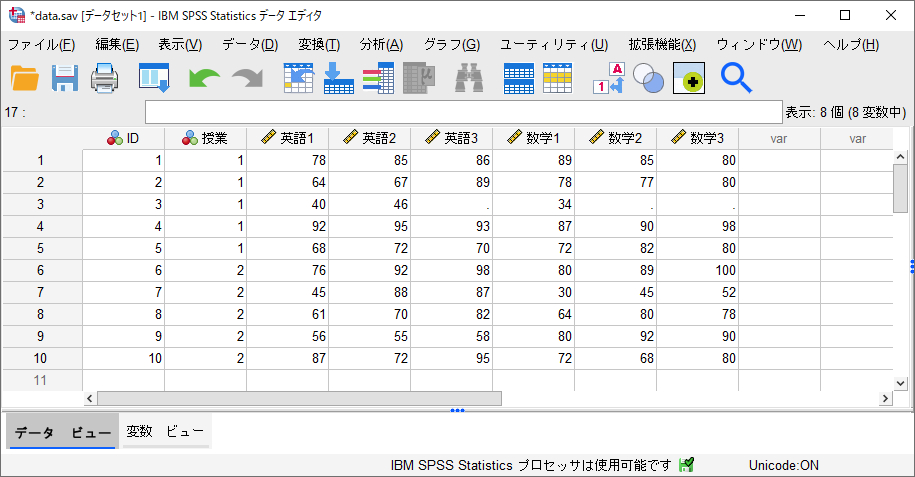 上記のデータファイルは、横持ち形式の例として、「ID」、「授業」(1:従来の授業法、2:新しい授業法)、「英語1」「英語2」「英語3」(1回目~3回目の英語の得点)、「数学1」「数学2」「数学3」(1回目~3回目の数学の得点)の8個の変数を含んでいます。IDの値に重複はなく、1人1ケースのデータになっていて、3回分のテスト結果が横に入力されていることが分かります。縦持ち形式との大きな違いとして、1回目~3回目のテストを区別するための「時点」の変数がなく、1回目・2回目・3回目の結果はそれぞれ変数を分けて入力されています。このデータファイルのケース数は10(n=10)で、10人分のデータを記録しています。
横持ち形式の場合、対応のあるt検定や反復測定分散分析を適用できますが、一般化線型モデルや混合効果モデルを使いたい場合は、縦持ち形式に持ち直す必要があります。また、グラフ作成を必要とする場合にも、内容によっては縦持ちに変換する場面があります。
ここでは、横持ち形式のデータファイルを、縦持ち形式のデータファイルに変換する手順をご紹介します。
■ 複数の従属変数を持つ横持ちデータの再構成手順
(1) 「データ」メニュー>「再構成」を選択します。
上記のデータファイルは、横持ち形式の例として、「ID」、「授業」(1:従来の授業法、2:新しい授業法)、「英語1」「英語2」「英語3」(1回目~3回目の英語の得点)、「数学1」「数学2」「数学3」(1回目~3回目の数学の得点)の8個の変数を含んでいます。IDの値に重複はなく、1人1ケースのデータになっていて、3回分のテスト結果が横に入力されていることが分かります。縦持ち形式との大きな違いとして、1回目~3回目のテストを区別するための「時点」の変数がなく、1回目・2回目・3回目の結果はそれぞれ変数を分けて入力されています。このデータファイルのケース数は10(n=10)で、10人分のデータを記録しています。
横持ち形式の場合、対応のあるt検定や反復測定分散分析を適用できますが、一般化線型モデルや混合効果モデルを使いたい場合は、縦持ち形式に持ち直す必要があります。また、グラフ作成を必要とする場合にも、内容によっては縦持ちに変換する場面があります。
ここでは、横持ち形式のデータファイルを、縦持ち形式のデータファイルに変換する手順をご紹介します。
■ 複数の従属変数を持つ横持ちデータの再構成手順
(1) 「データ」メニュー>「再構成」を選択します。
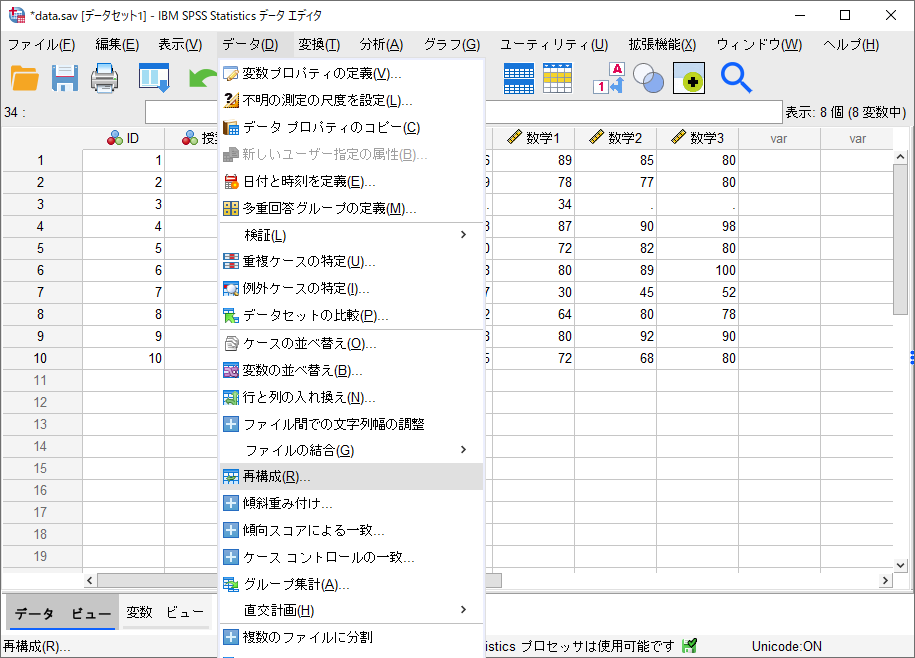 (2)「選択された変数をケースに再構成する」を選択して、「次へ」ボタンをクリックします。
(2)「選択された変数をケースに再構成する」を選択して、「次へ」ボタンをクリックします。
 横持ち形式→縦持ち形式に変換する場合は、「選択された変数をケースに再構成する」を使用します。この例では行いませんが、縦持ち形式→横持ち形式に変換する場合は2つ目のラジオボタンにある「選択されたケースを変数に再構成する」を使用します。
(3)「再構成する変数グループの数」として「複数」を選択して「数」ボックスに「2」と入力します。
横持ち形式→縦持ち形式に変換する場合は、「選択された変数をケースに再構成する」を使用します。この例では行いませんが、縦持ち形式→横持ち形式に変換する場合は2つ目のラジオボタンにある「選択されたケースを変数に再構成する」を使用します。
(3)「再構成する変数グループの数」として「複数」を選択して「数」ボックスに「2」と入力します。
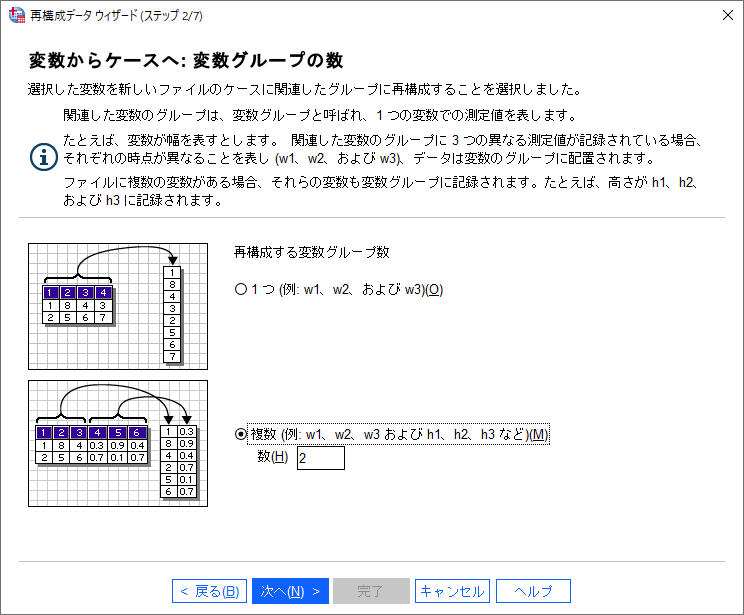 このステップは、横持ち形式→縦持ち形式への再構成で重要なステップの1つです。再構成する変数グループの数は、従属変数の数に依存します。この例では、「英語」と「数学」の2つのテスト結果が含まれているため、再構成される従属変数の数は2つです。したがって、変数グループの数は「2」になります。横持ちデータを縦持ちデータに変換する際のポイントは、この再構成する変数グループの数を適切に指定する必要があります。
(4) 「次へ」ボタンをクリックします。
このステップは、横持ち形式→縦持ち形式への再構成で重要なステップの1つです。再構成する変数グループの数は、従属変数の数に依存します。この例では、「英語」と「数学」の2つのテスト結果が含まれているため、再構成される従属変数の数は2つです。したがって、変数グループの数は「2」になります。横持ちデータを縦持ちデータに変換する際のポイントは、この再構成する変数グループの数を適切に指定する必要があります。
(4) 「次へ」ボタンをクリックします。
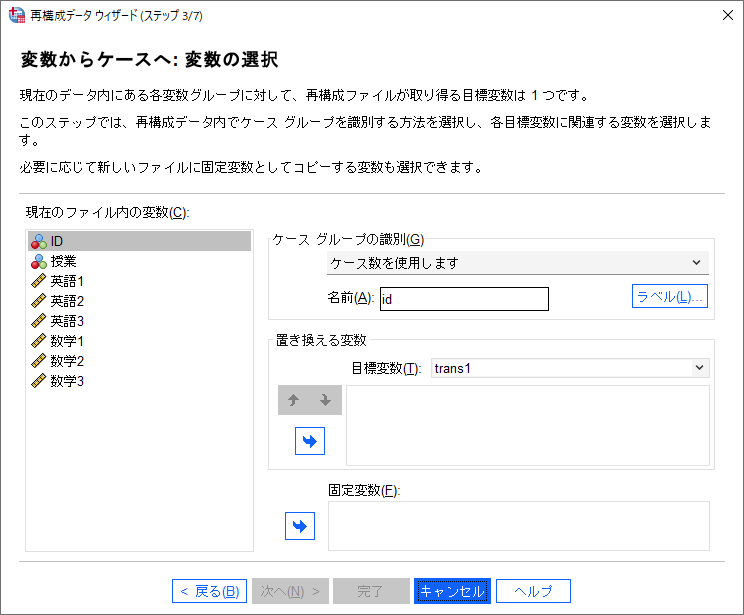 このステップで、ケースグループを識別する方法と置き換える変数の指定を行います。
(5) 「ケースグループの識別」ドロップダウンのリストをクリックします。
(6) 「選択された変数を使用します」を選択します。
(7) 「変数」ボックスに「ID」を移動します。
このステップで、ケースグループを識別する方法と置き換える変数の指定を行います。
(5) 「ケースグループの識別」ドロップダウンのリストをクリックします。
(6) 「選択された変数を使用します」を選択します。
(7) 「変数」ボックスに「ID」を移動します。
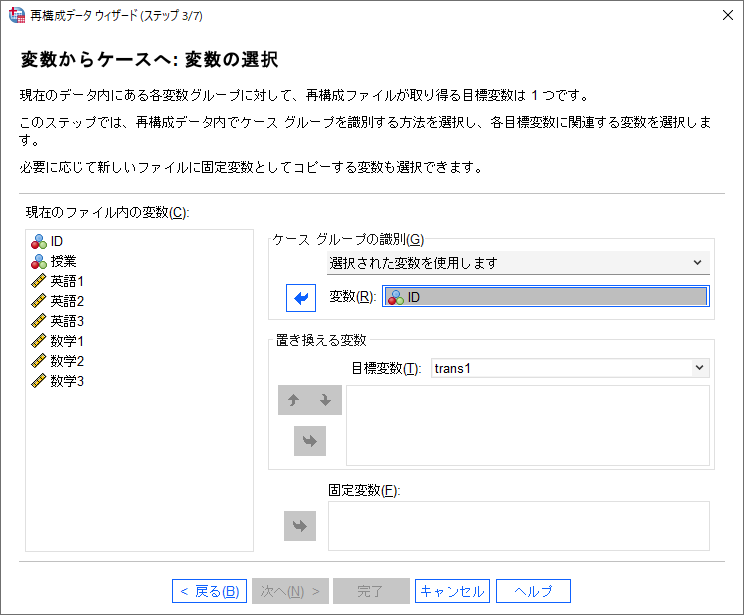 (8) 「置き換える変数」ボックスに「英語1」「英語2」「英語3」を移動します。
(9) 「目標変数」ボックスの名前を「trans1」から「英語」に変更します。
(8) 「置き換える変数」ボックスに「英語1」「英語2」「英語3」を移動します。
(9) 「目標変数」ボックスの名前を「trans1」から「英語」に変更します。
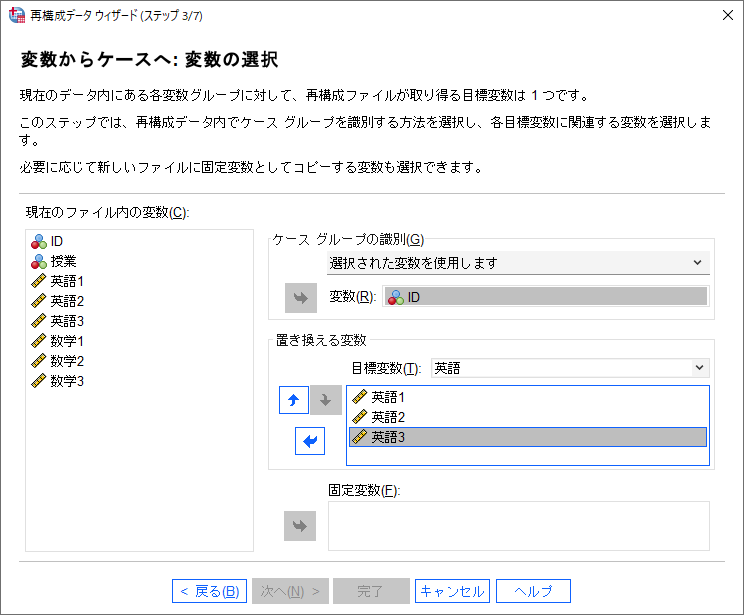 「目標変数」のドロップダウンリストには、縦持ち形式に変換した際の従属変数の新しい変数名を入力します。この例では、「英語1」「英語2」「英語3」の3つの変数を「英語」という名称の新しい変数に統合するための設定を行いました。次に、「数学1」「数学2」「数学3」の3つの変数を「数学」という名称の変数に統合するための設定を行います。
(10) 「目標変数」ドロップダウンリストから「trans2」を選択します。
「目標変数」のドロップダウンリストには、縦持ち形式に変換した際の従属変数の新しい変数名を入力します。この例では、「英語1」「英語2」「英語3」の3つの変数を「英語」という名称の新しい変数に統合するための設定を行いました。次に、「数学1」「数学2」「数学3」の3つの変数を「数学」という名称の変数に統合するための設定を行います。
(10) 「目標変数」ドロップダウンリストから「trans2」を選択します。
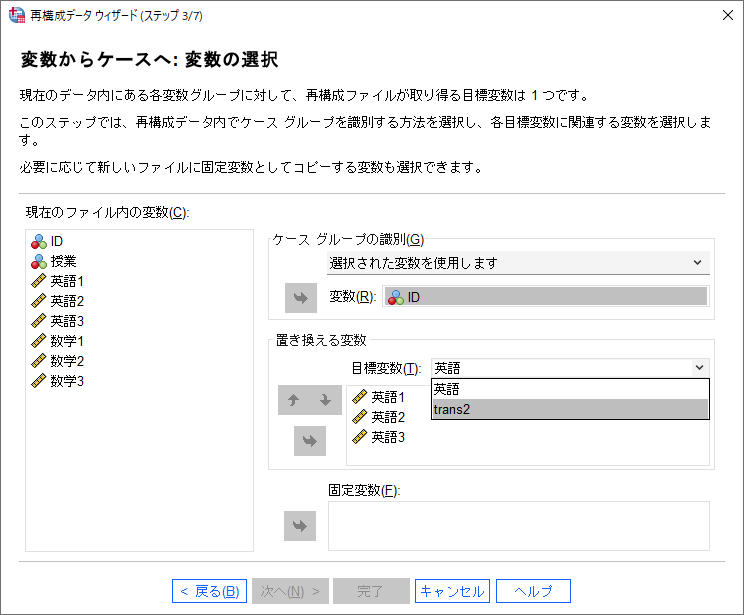 このとき、「trans2」が選べるのは、1つ前のステップで「再構成する変数グループの数」を「2」としているからです。
(11) 「置き換える変数」ボックスに「数学1」「数学2」「数学3」を移動します。
(12) 「目標変数」ボックスの名前を「trans2」から「数学」に変更します。
このとき、「trans2」が選べるのは、1つ前のステップで「再構成する変数グループの数」を「2」としているからです。
(11) 「置き換える変数」ボックスに「数学1」「数学2」「数学3」を移動します。
(12) 「目標変数」ボックスの名前を「trans2」から「数学」に変更します。
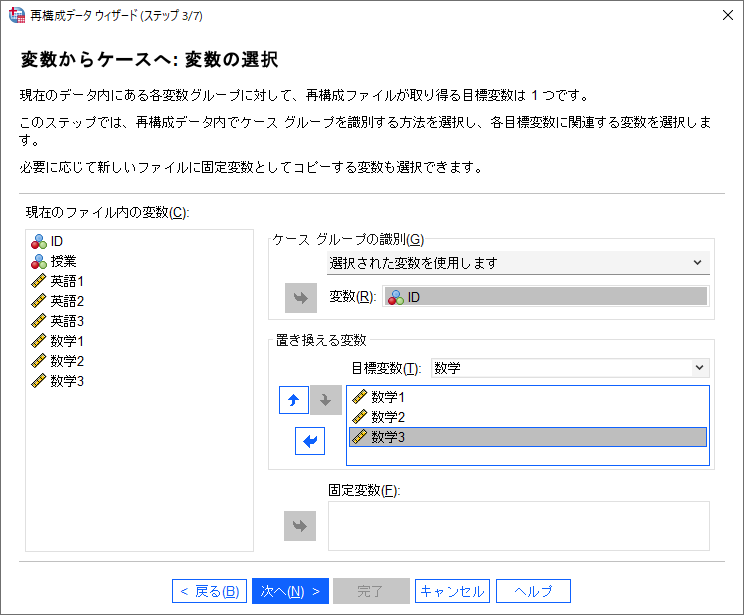 (13) 「固定変数」ボックスに「授業」を移動します。
(13) 「固定変数」ボックスに「授業」を移動します。
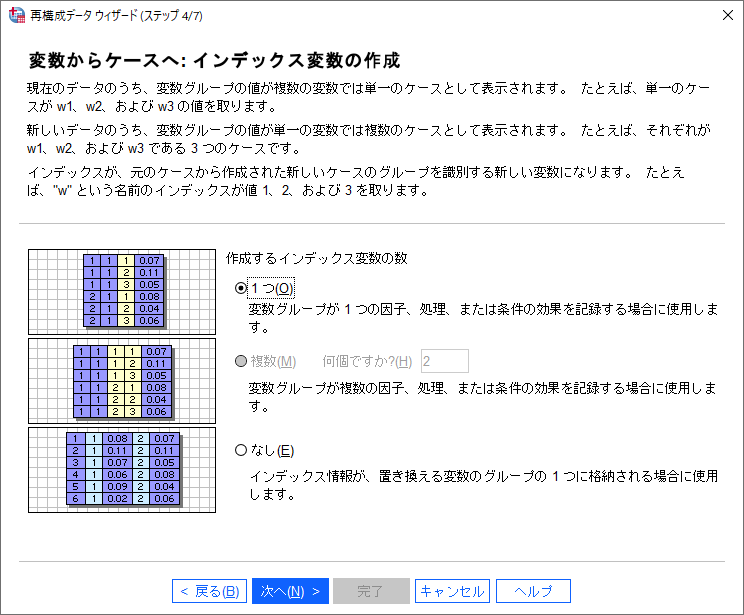
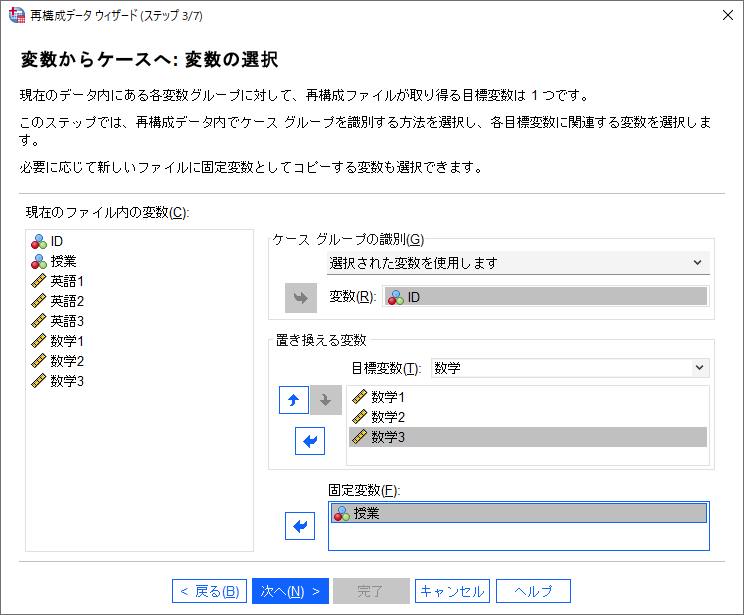 (14) 「作成するインデックス変数の数」を「1つ」のまま「次へ」ボタンをクリックします。
(14) 「作成するインデックス変数の数」を「1つ」のまま「次へ」ボタンをクリックします。
 (15) インデックス変数の「名前」に「時点」と入力します。
(15) インデックス変数の「名前」に「時点」と入力します。
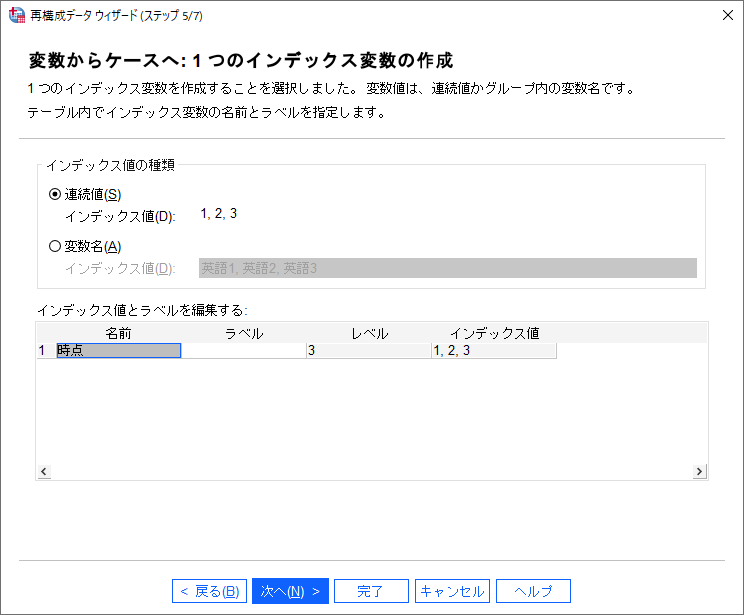 インデックス変数は、データファイルを縦持ち形式に変換した際の、時点や回数を意味する変数です。この例では、1回目・2回目・3回目の各時点を意味する変数になります。「名前」には作成するインデックス変数の名前を入力します。この名前は自分でわかればよく任意の名称で問題ありませんが、変数名になりますので「先頭1文字目に数字や記号を使えない」「すでに存在する変数名と重複する名称は使えない」など、変数名の通常の命名規則に従います。また、「ラベル」は変数を補足説明するための変数ラベルを入力しますが、ブランクのままでも問題ありませんし、データファイルを変換した後にラベルを付けたり変更したりすることもできます。
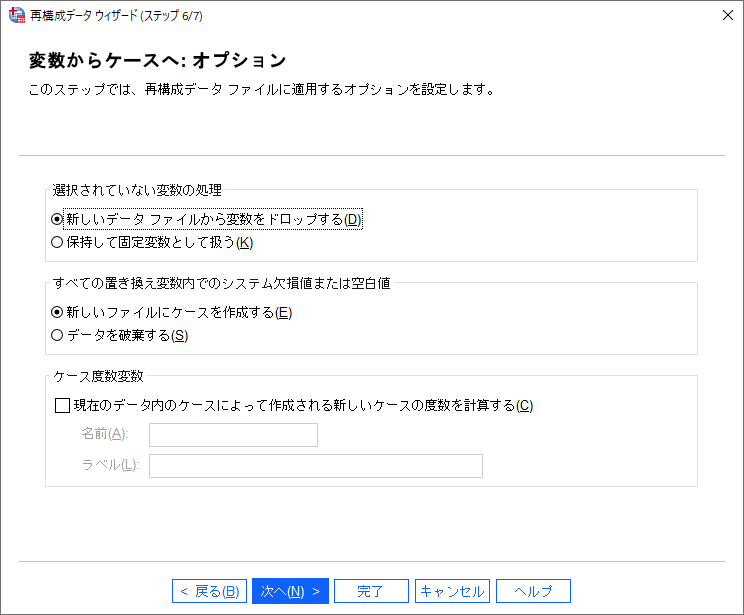
(16) 「選択されていない変数の処理」は特に変更せず「完了」ボタンをクリックします。
インデックス変数は、データファイルを縦持ち形式に変換した際の、時点や回数を意味する変数です。この例では、1回目・2回目・3回目の各時点を意味する変数になります。「名前」には作成するインデックス変数の名前を入力します。この名前は自分でわかればよく任意の名称で問題ありませんが、変数名になりますので「先頭1文字目に数字や記号を使えない」「すでに存在する変数名と重複する名称は使えない」など、変数名の通常の命名規則に従います。また、「ラベル」は変数を補足説明するための変数ラベルを入力しますが、ブランクのままでも問題ありませんし、データファイルを変換した後にラベルを付けたり変更したりすることもできます。
(16) 「選択されていない変数の処理」は特に変更せず「完了」ボタンをクリックします。
 (17) 確認のメッセージは「OK」ボタンをクリックして閉じます。
(17) 確認のメッセージは「OK」ボタンをクリックして閉じます。
 以下のように、縦持ち形式に変換されたデータファイルが表示されます。従属変数として、「英語」と「数学」の2つの変数に再構成されたことが分かります。
以下のように、縦持ち形式に変換されたデータファイルが表示されます。従属変数として、「英語」と「数学」の2つの変数に再構成されたことが分かります。
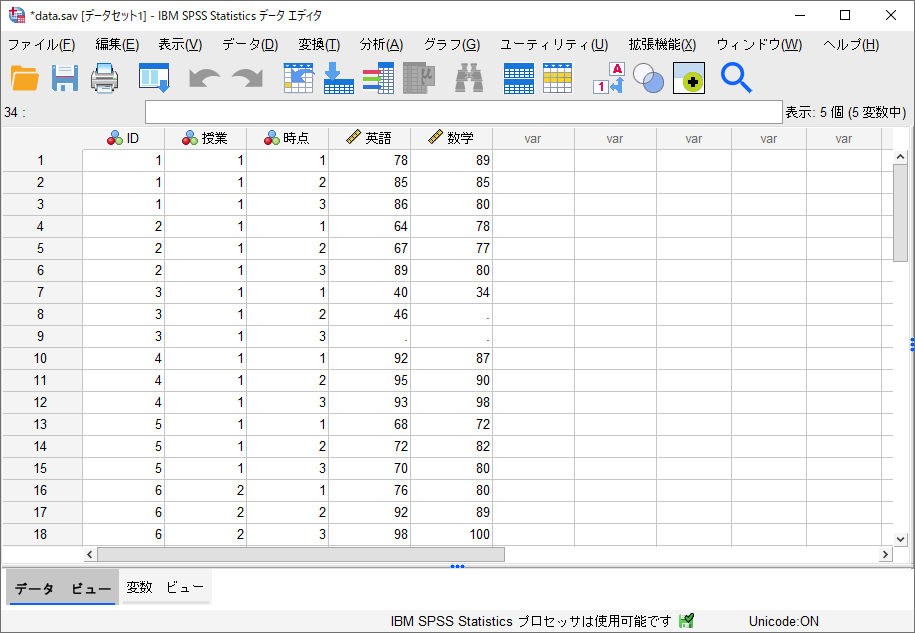 このように、データの再構成を使用することで、比較的簡単な手順で横持ち形式を縦持ち形式に変換することができます。基本的に、縦持ち形式に変換した後のデータファイルの従属変数は1つになりますが、この例では2つの従属変数を持つデータの加工方法についてご紹介しました。
目的や使い方、用途に応じて、IBM SPSS製品を有効にご活用いただき、課題解決・価値創造にお役立てください。
このように、データの再構成を使用することで、比較的簡単な手順で横持ち形式を縦持ち形式に変換することができます。基本的に、縦持ち形式に変換した後のデータファイルの従属変数は1つになりますが、この例では2つの従属変数を持つデータの加工方法についてご紹介しました。
目的や使い方、用途に応じて、IBM SPSS製品を有効にご活用いただき、課題解決・価値創造にお役立てください。
上記のデータファイルは、縦持ち形式の例として、「ID」、「授業」(1:従来の授業法、2:新しい授業法)、「時点(1:1回目、2:2回目、3:3回目)」、「英語」の得点、「数学」の得点の5個の変数を含んでいます。IDの値に重複があり(1人が複数行にまたがって入力されており)、1人の3回分のテスト結果が縦に入力されていることが分かります。横持ち形式との大きな違いとして、1回目~3回目のテストを区別する変数として「時点」を持ちます。このデータファイルのケース数は30(n=30)で、10人分の合計3回のテスト結果のデータを記録しています。
この内容と全く同じデータを、以下のように横持ち形式で入力することもできます。
■ 横持ち形式(変数グループ/ワイド形式)のデータファイルの例:(ケース数=10)
上記のデータファイルは、横持ち形式の例として、「ID」、「授業」(1:従来の授業法、2:新しい授業法)、「英語1」「英語2」「英語3」(1回目~3回目の英語の得点)、「数学1」「数学2」「数学3」(1回目~3回目の数学の得点)の8個の変数を含んでいます。IDの値に重複はなく、1人1ケースのデータになっていて、3回分のテスト結果が横に入力されていることが分かります。縦持ち形式との大きな違いとして、1回目~3回目のテストを区別するための「時点」の変数がなく、1回目・2回目・3回目の結果はそれぞれ変数を分けて入力されています。このデータファイルのケース数は10(n=10)で、10人分のデータを記録しています。
横持ち形式の場合、対応のあるt検定や反復測定分散分析を適用できますが、一般化線型モデルや混合効果モデルを使いたい場合は、縦持ち形式に持ち直す必要があります。また、グラフ作成を必要とする場合にも、内容によっては縦持ちに変換する場面があります。
ここでは、横持ち形式のデータファイルを、縦持ち形式のデータファイルに変換する手順をご紹介します。
■ 複数の従属変数を持つ横持ちデータの再構成手順
(1) 「データ」メニュー>「再構成」を選択します。
(2)「選択された変数をケースに再構成する」を選択して、「次へ」ボタンをクリックします。
横持ち形式→縦持ち形式に変換する場合は、「選択された変数をケースに再構成する」を使用します。この例では行いませんが、縦持ち形式→横持ち形式に変換する場合は2つ目のラジオボタンにある「選択されたケースを変数に再構成する」を使用します。
(3)「再構成する変数グループの数」として「複数」を選択して「数」ボックスに「2」と入力します。
このステップは、横持ち形式→縦持ち形式への再構成で重要なステップの1つです。再構成する変数グループの数は、従属変数の数に依存します。この例では、「英語」と「数学」の2つのテスト結果が含まれているため、再構成される従属変数の数は2つです。したがって、変数グループの数は「2」になります。横持ちデータを縦持ちデータに変換する際のポイントは、この再構成する変数グループの数を適切に指定する必要があります。
(4) 「次へ」ボタンをクリックします。
このステップで、ケースグループを識別する方法と置き換える変数の指定を行います。
(5) 「ケースグループの識別」ドロップダウンのリストをクリックします。
(6) 「選択された変数を使用します」を選択します。
(7) 「変数」ボックスに「ID」を移動します。
(8) 「置き換える変数」ボックスに「英語1」「英語2」「英語3」を移動します。
(9) 「目標変数」ボックスの名前を「trans1」から「英語」に変更します。
「目標変数」のドロップダウンリストには、縦持ち形式に変換した際の従属変数の新しい変数名を入力します。この例では、「英語1」「英語2」「英語3」の3つの変数を「英語」という名称の新しい変数に統合するための設定を行いました。次に、「数学1」「数学2」「数学3」の3つの変数を「数学」という名称の変数に統合するための設定を行います。
(10) 「目標変数」ドロップダウンリストから「trans2」を選択します。
このとき、「trans2」が選べるのは、1つ前のステップで「再構成する変数グループの数」を「2」としているからです。
(11) 「置き換える変数」ボックスに「数学1」「数学2」「数学3」を移動します。
(12) 「目標変数」ボックスの名前を「trans2」から「数学」に変更します。
(13) 「固定変数」ボックスに「授業」を移動します。
(14) 「作成するインデックス変数の数」を「1つ」のまま「次へ」ボタンをクリックします。
(15) インデックス変数の「名前」に「時点」と入力します。
インデックス変数は、データファイルを縦持ち形式に変換した際の、時点や回数を意味する変数です。この例では、1回目・2回目・3回目の各時点を意味する変数になります。「名前」には作成するインデックス変数の名前を入力します。この名前は自分でわかればよく任意の名称で問題ありませんが、変数名になりますので「先頭1文字目に数字や記号を使えない」「すでに存在する変数名と重複する名称は使えない」など、変数名の通常の命名規則に従います。また、「ラベル」は変数を補足説明するための変数ラベルを入力しますが、ブランクのままでも問題ありませんし、データファイルを変換した後にラベルを付けたり変更したりすることもできます。
(16) 「選択されていない変数の処理」は特に変更せず「完了」ボタンをクリックします。
(17) 確認のメッセージは「OK」ボタンをクリックして閉じます。
以下のように、縦持ち形式に変換されたデータファイルが表示されます。従属変数として、「英語」と「数学」の2つの変数に再構成されたことが分かります。
このように、データの再構成を使用することで、比較的簡単な手順で横持ち形式を縦持ち形式に変換することができます。基本的に、縦持ち形式に変換した後のデータファイルの従属変数は1つになりますが、この例では2つの従属変数を持つデータの加工方法についてご紹介しました。
目的や使い方、用途に応じて、IBM SPSS製品を有効にご活用いただき、課題解決・価値創造にお役立てください。
■ IBM SPSS Statistics Base IBM SPSS Statisticsによるデータ入力、読込み、データ加工、基本統計量の出力、推測統計(仮説検定・信頼区間)、回帰分析、因子分析、クラスター分析、分散分析、グラフ作成、外部ファイルへのエクスポート、拡張機能などを有する基本モジュール https://www.stats-guild.com/ibm-spss
■ E-Learningコース SPSSによる統計解析を学習するための ハンズオン形式のE-Learningコース(Textbook付属) https://www.stats-guild.com/spss-e-learning-textbook
■ SPSS 講習会 E-Learningと集合タイプ講義をブレンドしたスタイルの講習会 https://www.stats-guild.com/l-room
