K-meansクラスター分析とは
非階層的クラスタリング手法
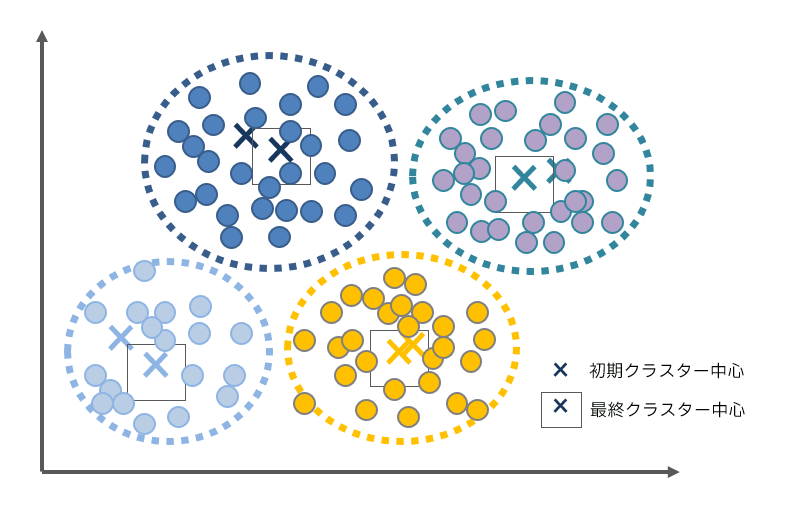
K-meansクラスター分析は、データを事前に指定した数(K個)のクラスターに分類する非階層的クラスタリング手法です。各ケースとクラスター中心との距離(ユークリッド距離)を計算し、最も近いクラスター中心に割り当てます。その後、割り当てられたケースの平均値でクラスター中心を更新し、この処理を収束するまで繰り返します。下記は、初期クラスター中心(黒い×印)から反復計算を経て、最終クラスター中心(色付きの×印)へ更新される計算のイメージ図です。
K-meansクラスター分析は、購買行動や属性に基づく顧客セグメンテーション、製品やサービスの市場ポジショニング、ピクセルの色に基づく画像の領域分割、正常なパターンから外れたデータの異常検出など、幅広い場面で活用されています。
K-meansクラスター分析の手順
分類 > K-meansクラスター
ある企業が保有している顧客情報のサンプルデータを用いて、契約状況や家や車の所有状況の変数に基づいて、顧客を3つのセグメントに分類してみます。
メニュー選択
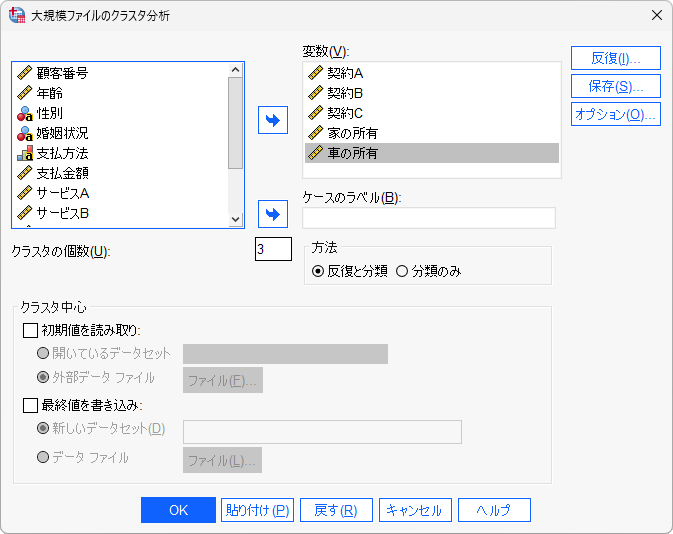
- 1.「分析」メニュー > 「分類」 > 「大規模ファイルのクラスタ」を選択します
- 2.「変数」にクラスター分析で使用する変数を指定します
- 3.「クラスタの個数」に分類するクラスター数(任意の数。この例では3)を入力します
クラスター数の決定は、分析の目的や解釈のしやすさ、事前の知識などを考慮して行います。最適なクラスター数は、事前には分からないことが多いため、結果をみながらクラスター数を試行錯誤することになります。
反復と分類の設定
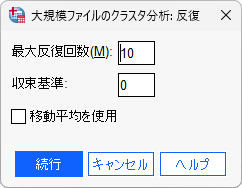
- 4.「反復」ボタンをクリックします
- 5.「最大反復回数」を設定します(デフォルトは10)
- 6.「収束基準」を設定します(デフォルトは0)
最大反復回数は、クラスター分析の実行で反復計算される回数の上限数で、デフォルトは「10」です。回数内に反復計算が終了すると「反復の記述」テーブルの下部に「収束が完了しました」と表示されます。回数を超えた場合は「収束に失敗しました」と表示され、この結果は信頼できません。
収束基準は、クラスター中心の変化がこの値以下になったときに収束と判断する基準です。0を指定すると、クラスター中心が全く変化しなくなるまで反復を続けます。
保存の設定
- 7.「保存」ボタンをクリックします
- 8.「所属クラスタ」にチェックを入れます
所属クラスタを選択すると、各ケースが属するクラスター番号が新しい変数としてデータに保存されます。この変数を使用して、クラスターごとの特性を分析したり、クロス集計を行ったりすることができます。
分析の実行
- 9.「続行」ボタンを選択します
- 10.「OK」ボタンをクリックします
結果の確認
反復の記述
反復の記述テーブルには、どのようにクラスター中心を修正しながら収束したかを確認するための重要な出力です。収束が完了したかどうかは、テーブル下部のメッセージを確認します。
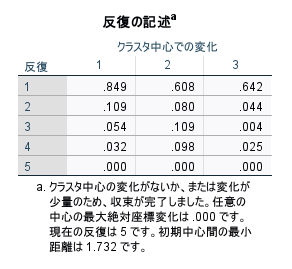
今回は「クラスタ中心の変化がないか、または変化が少量のため、収束が完了しました」との記載があり、指定した最大反復回数内に収束基準を満たし、収束が完了したことが分かります。
最終クラスタ中心
最終クラスタ中心テーブルには、各クラスターに属するケースの各変数の平均値が表示されており、最終クラスター中心と呼ばれます。この値を基準にして、クラスターの分類が行われます。
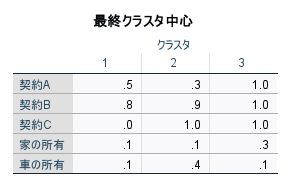
最終クラスター中心の値は、各クラスターの特徴を定量的に示す重要な手がかりです。高い値が並ぶ項目に注目し、どのような特徴の集団かを読み取り、各クラスターに適切な名前を付けましょう。
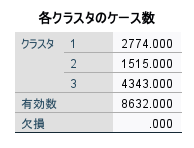
各クラスタのケース数
各クラスタのケース数テーブルには、各クラスターに分類されたケースの数が表示されます。極端にケース数が少ないクラスターがある場合は、クラスター数の見直しや外れ値の確認が必要かもしれません。