
ランダムフォレスト
|Random Forest
ランダムフォレスト
Random Forest
データの分類や回帰分析に使用されるアンサンブル学習アルゴリズムの一種です。複数の決定木(Decision Trees)を組み合わせることで、単独の決定木よりも高い予測精度を得ることができる強力な手法です。特に、過学習(overfitting)を抑えつつ、モデルの汎化性能を向上させることに優れています。
A type of ensemble learning algorithm used for classification and regression tasks. It combines multiple decision trees to achieve higher predictive accuracy than a single decision tree. This powerful method is especially effective at improving model generalization while reducing overfitting.
高い予測精度を持つアンサンブル学習手法
ランダムフォレスト(Random forest, RF)は、ディシジョンツリー(Decision tree;決定木)に基づいた機械学習の代表的な手法です。重複を許すランダムサンプリングによって多数のディシジョンツリーを作成し、各ツリーの予測結果の多数決をとることで最終予測値を決定します。 大きな特徴として、レコードだけではなく特徴量(入力フィールド)もサンプリングされるため、候補となる特徴量が非常に多いデータセットでも比較的高速にツリーが作成され、各ツリーの多様性と高い予測精度が期待できます。
複数のツリーをランダムに構築して、それらの結果を組み合わせるので、集団学習やアンサンブル学習とも呼ばれます。
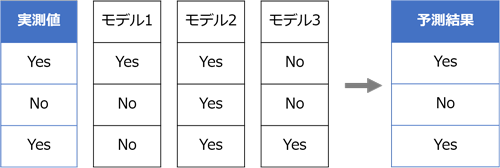
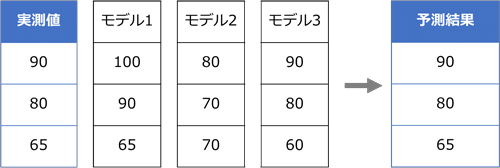
アンサンブル学習は、複数のモデルを使用した集団学習によってモデルのバイアス(Bias;偏り)やバリアンス(Variance;ばらつき)を小さく抑えて精度を向上させる方法です。アンサンブル学習の基本的な考え方は、簡単に言えば多数決です。異なるモデルを複数作成し、その結果を結合させることで予測精度を高めます。予測対象がカテゴリ型の場合は多数決によって最終的な予測結果を決定します。
予測対象が連続型の場合は各モデルの平均をとります。
アンサンブル学習では複数のモデルの結果を使用しますが、仮に、それぞれのモデルが全く同じ構造だった場合は予測値もすべて同じとなり予測精度は向上しませんので、モデルの多様性が必要です。アンサンブル学習でよく用いられる手法に、バギング(Bagging)とブースティング(Boosting)があります。
バギングやブースティングとの違い
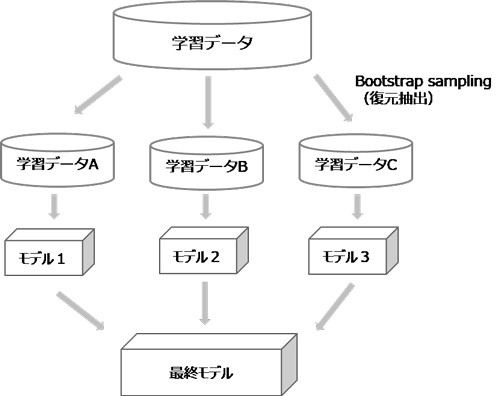
バギングは、モデルの予測結果のバリアンスを小さくする特徴があります。ブートストラップサンプリング(復元抽出)によって学習データの一部を使用した複数のデータセットを生成し、複数のモデルを作成してアンサンブルする方法です。サンプリングされた複数のデータセットはそれぞれ内容が異なるため、作成されるモデルも多様化します。その平均をとることで各データの予測値のばらつきを小さくします。
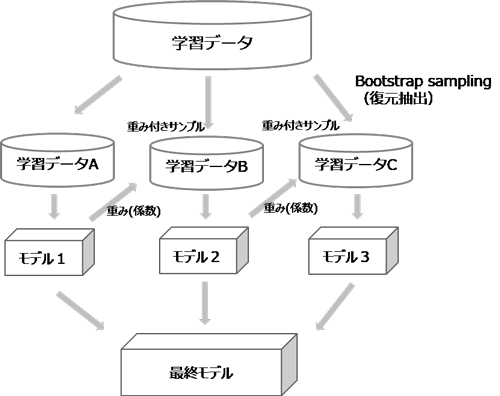
ブースティングは、モデルのバイアスを小さくする特徴があります。バギングと同様にサンプリングによって複数の学習データセットを生成しますが、モデルを1つずつ順番に作成し、誤分類したデータを優先的に当てるように次のデータセットに重みを付けて調整し、これを繰り返し行い、複数のモデルを作成してアンサンブルする方法です。最初に作ったモデルがベースとなり、そのモデルに対して反復処理を行って複数のモデルを作成することでモデルの偏りが小さくなります。前のモデルの結果を考慮して次のモデルの重みを調整しているため、バギングのような並列処理ができず計算に時間がかかります。
ランダムフォレストはバギングの一種で、モデルの予測結果のバリアンスを小さくする特徴があります。バギングとの違いは、「レコード」と「特徴量(フィールド/説明変数)」の両方をサンプリングしている点です。バギングでは同じ特徴量を使用してモデルを作成するため、データセットによっては似たモデルが作られ、モデル間の相関が強くなる場合がありますが、ランダムフォレストでは特徴量もサンプリングすることでモデル間の相関が低くなり、バギングよりもモデルの多様性が高くなり、バリアンスも小さくなります。
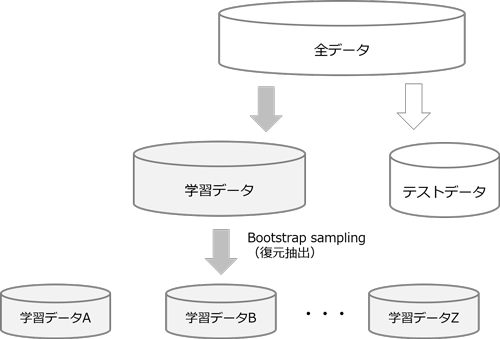
まず、ブートストラップサンプリング(復元抽出)により複数の学習データセットを生成し、学習データセットごとにランダムにK個の特徴量を選択し、ディシジョンツリーをN個作成します。最後にN個のディシジョンツリーの結果をアンサンブルにより結合する流れです。
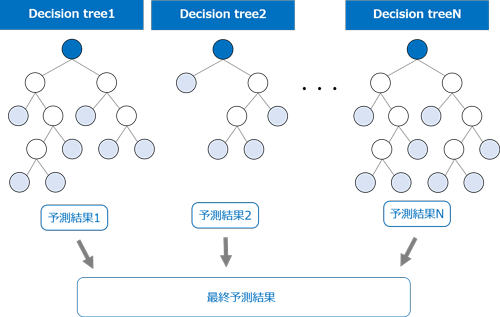
ディシジョンツリーは、ツリーが深くなると構造が複雑になりオーバーフィットが起きやすいという問題がありますが、ランダムフォレストはアンサンブル学習によりディシジョンツリーよりも汎化性能(未知のデータに対して正解する能力)に優れ、テストデータへのあてはまりが良くなります。そのため、オーバーフィットが起きにくく、テストデータの予測精度向上が期待できます。
ソフトウェア
SPSSでは標準機能では対応しておらず、RパッケージのrandomForestパッケージを利用した拡張機能SPSSINV RANFORで対応します。なお、SPSS Modelerには標準実装されておりStatisticsよりお奨めです。Rでは、randomForestパッケージやrangerパッケージを使用します。Pythonでは、scikit-learnで実装できます。
参考文献
- Breiman, L. (2001). Random forests. Machine Learning, 45(1), 5-32.
- Geurts, P., Ernst, D., & Wehenkel, L. (2006). Extremely randomized trees. Machine Learning, 63(1), 3-42.
- Trevor Hastie,Robert Tibshirani,Jerome Friedman,杉山将(監訳)(2014),統計的学習の基礎 ―データマイニング・推論・予測,共立出版