Classification and Regression Tree
- 分析手法の種類
- 予測する
- 要因を探る
- 比較する
- 分類する
- 集計する
- 可視化する
不純度に基づく決定木の手法
C&R Tree(CRT)は、目的変数に対して多数の要因でデータセットをセグメントに分岐し、ツリー図を構築する分析手法です。変数の選択や分岐の基準に不純度を用いており、CHAIDと並びよく利用されるディシジョンツリーの手法ですが、分岐は常に2つになるのが特徴です。 目的変数には、カテゴリ変数(比率)とスケール変数(平均値)の両方が利用できます。
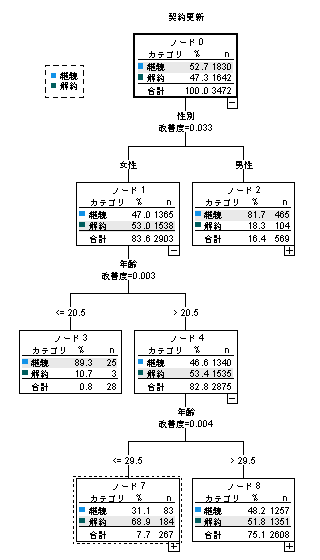
目的変数がカテゴリカルデータの場合、パーセンテージを代表値として観測データを分類するためのルールを作ります。各分割点で最適な変数を選び、データを最も純粋なグループに分割します。分割の基準は不純度(Gini Impurity)がよく使われます。不純度はデータがどれだけ混在しているかを示す指標で、0に近いほど1つのカテゴリに偏っていることを示します。
目的変数が連続データの場合、平均値を代表値としてCRTは回帰木を作成します。各分割点で、分割前後のグループ間の分散の減少量(分散減少率)を基に最適な分割を決定します。
決定木は、分割を続けるとデータに完全に適合し、過学習(overfitting)が発生する可能性があります。これを防ぐために、木を剪定(pruning)して、モデルの複雑さをコントロールします。
ソフトウェア
SPSSでは、Decision Treesオプションで決定木分析の各手法に対応します。なお、SPSS Modelerの方が機能が充実しており予測に使用する場合に向いています。Rでは、rpartパッケージを使用します。Pythonでは、sklearnのDecisionTreeClassifierやDecisionTreeRegressorを使用してCRTを実装できます。
参考文献
- Breiman, L., Friedman, J. H., Olshen, R. A., & Stone, C. J. (1984). Classification and Regression Trees. Wadsworth International Group.
- 滋賀大学データサイエンス学部(2024),この1冊ですべてわかる データサイエンスの基本,日本実業出版社
- IBM_SPSS_Decision_Trees.pdf