ファイルの結合-変数の追加
1データセット結合の準備
データの確認とデータセット名の変更
この例では、簡単なサンプルとして「顧客情報」(「ID」と「性別」)と「購入金額」(「ID」と「購入金額」)の2つのデータファイルを結合します。両方のファイルに共通して含まれるID変数をキー変数として使用して結合を行います。キー変数は名前とデータ型が一致している必要があります。
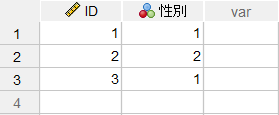
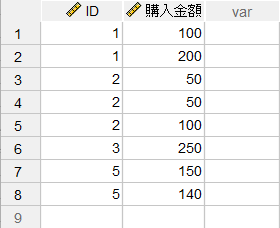
さらに、データセット名を事前に変更しておくと作業内容がより分かりやすくなります(デフォルトのデータセット名は、データファイルを開いた順番にデータセット1、データセット2のように定義されます)。データセット名の変更は、「ファイル」>「データセット名の変更」メニューを使用します。
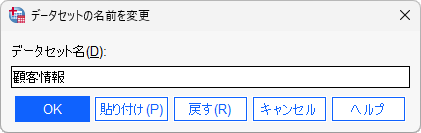
「データセット名の変更」メニュー
- 「ファイル」メニュー >「データセット名の変更」を選択します
- 「顧客情報」と入力します
- 「OK」ボタンをクリックします
同様の手順でもう一方のデータセットの名前を「購入金額」に変更しておきます。
2変数の追加
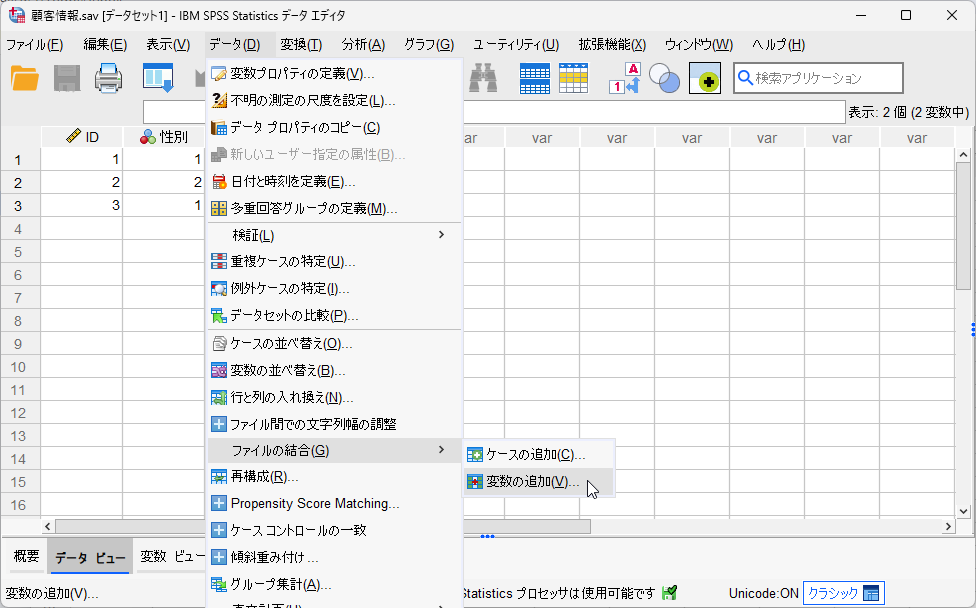
「データ」>「ファイルの結合」>「変数の追加」
ファイル結合に際して、IBM SPSS Statistics形式のデータファイルの場合は、あらかじめファイルを開く必要はありませんが、ExcelやCSVなどの外部ファイル形式の場合は、一度SPSSに読み込んでおかなければなりません。
「変数の追加」メニュー
- 「データ」メニュー >「ファイルの結合」>「変数の結合」を選択します
結合するファイルの選択
- 「開いているデータセットの一覧」で対象を選択します
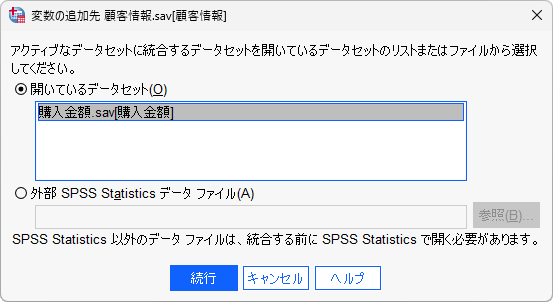
ここで、データセット名が番号([データセット1]など)ではなく名前([購入金額])と表示されているのは、事前にデータセット名を変更しているためです。
結合するファイルの選択
- 「続行」ボタンをクリックします
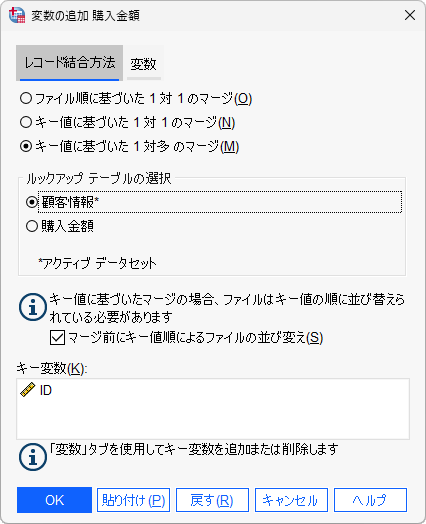
「変数の追加」ダイアログボックスが表示されます。キー変数として2つのファイルで同じ変数名のIDがすでに選択されていることが分かります。また、レコード結合方法として以下の3つが指定できます。
ファイル順に基づいた1対1のマージ
ケースの並び順に基づいて2つのファイルのケース同士を1:1の関係で結合します。ケースの並び順がずれているなど間違った結合となる危険性を持ち、あまり推奨されません。
キー値に基づいた1対1のマージ
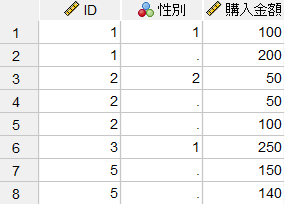
キー変数の値の一致を条件に、2つのファイルを1:1の関係で結合します。この方法では、互いのファイルのキー値は1回しか使用されず、重複したキー値は無視されます。この例で「キー値に基づいた1対1のマージ」によって結合するとその結果は以下のようになり、顧客情報と購入金額2つのデータセットのIDの値が、1:1の関係で結合されており、IDが重複している場合のケースは欠損値になります。なお、この方法の場合のシンタックスコードは「MATCH FILES /FILE=*」のように「/FILE」が指定されます。
キー値に基づいた1対多のマージ
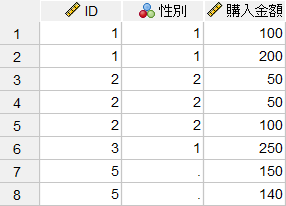
キー変数の値の一致を条件に、2つのファイルを1:多の関係で結合します。1:Nの結合とも呼ばれます。この方法では、一方のファイルのキー値は一意(ユニーク)で、もう一方のファイルのキー値が重複することを前提としています。キー値が一意(ユニーク)なファイルはルックアップテーブルと呼ばれます。もしこの例で「キー値に基づいた1対多のマージ」によって結合するとその結果は以下のようになり、顧客情報と購入金額2つのデータセットのIDの値が、1:多の関係で結合されており、IDが重複しているケースが有効値になります。なお、この方法の場合のシンタックスコードは「MATCH FILES /TABLE=*」のように「/TABLE」が指定されます。
この例では、1:Nの結合を実行します。
結合方法とルックアップテーブルの指定
- 「キー値に基づいた1対多のマージ」を選択します
- 「ルックアップテーブルの選択」に「顧客情報」を選択します
ルックアップテーブルは、キー変数の値が一意(ユニーク)なデータセットです(SPSSの古いバージョンでは「検索テーブル」と呼ばれていました)。この例では、顧客情報を含むデータセットが該当します。ルックアップテーブルを正しく指定しないと、ファイル結合が意図した結果にならない可能性があります。
また、変数の追加を行うためには、キー変数の値が昇順に並んでいる必要があるため、「マージ前にキー値順になるようファイルの並び替え」の機能が有効になっています(シンタックスでは「SORT CASES BY ID.」が自動的に追加されることになります)。この設定によって、ファイル結合の前に2つのファイルのキー変数の値がそれぞれ昇順に並び替えられます。もし、データファイルのキー変数が事前に昇順に並び替えられている場合は、並び替えを省略して処理時間を短縮させることも可能です。
結合する変数の選択
- 「変数」タブをクリックします
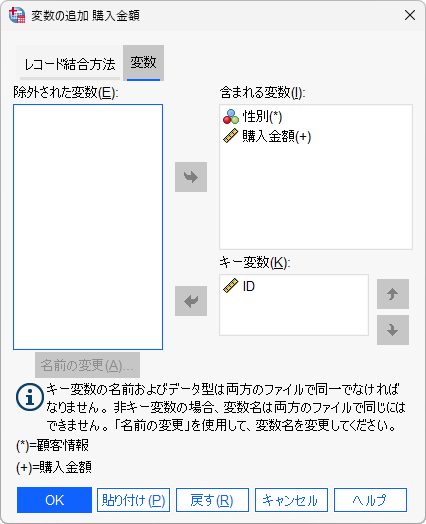
含まれる変数には、結合後の変数が表示されています。変数名の後ろについている記号(*)はその変数がアクティブデータセット(この例では[顧客情報])、(+)はその変数が追加されるデータセット(この例では[購入金額])から得られることを意味します。1つのファイルで同じ変数名を使うことは許されないため、名前が重複している変数は「除外された変数」にリストされます。変数を除外せずに結合後のデータファイルに含めたい場合は「名前の変更」を行います。
「キー変数」は、2つのファイルで名前が一致している変数を使用することができます。この例では、IDを使用しています。
変数の追加の実行
- 「OK」ボタンをクリックします
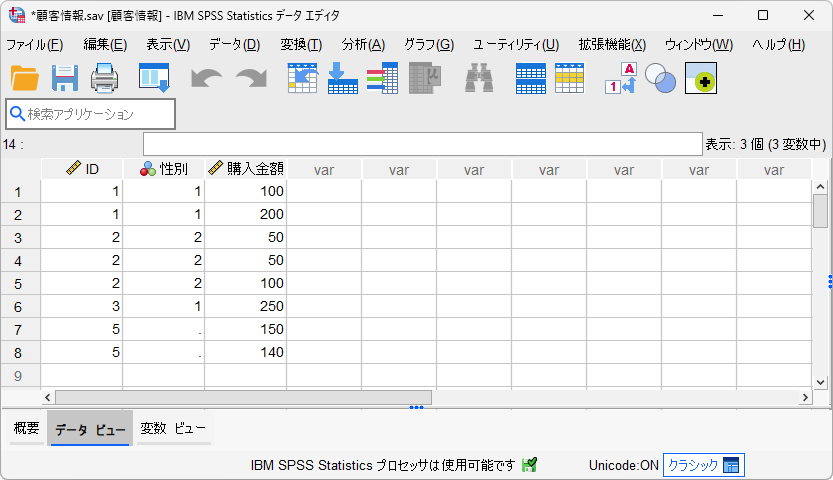
「顧客情報」と「購入金額」の2つのデータセットが結合されて「ID」「性別」「購入金額」の全ての変数が使用できるようになりました。顧客情報に含まれていないID=5のケースは「性別」の値がありませんので欠損値になっています(欠損値のケースを除外したい場合は、ケースの選択メニューを使用します)。
参考文献
- IBM_SPSS_Statistics_Core_System_User_Guide.pdf
- IBM_SPSS_Statistics_Command_Syntax_Reference.pdf