拡張ハブ「Propensity Score Matching」による傾向スコアマッチング
傾向スコアマッチング
この例では、傾向スコアの推定とマッチングが同時に行われる「Propensity Score Matching」メニューの方法を紹介します。インターフェイスが英語表記になりますが、「傾向スコアによる一致」メニューと基本的な手順や結果は同じです。
前提として、拡張機能である「Propensity Score Matching」がインストールされている必要があります。「データ」メニューに表示がない場合は、以下の手順を参考に拡張機能を追加インストールしてください。
拡張機能のインストール
拡張機能のインストール手順は簡単ですが、インターネット接続が必要です。オフラインのSPSSに拡張機能を追加する場合は、事前にインターネットに接続したPCで拡張機能をダウンロード後、ローカル拡張バンドルのインストールを行う方法を取ってください。拡張機能のインストールは無料で利用できます。
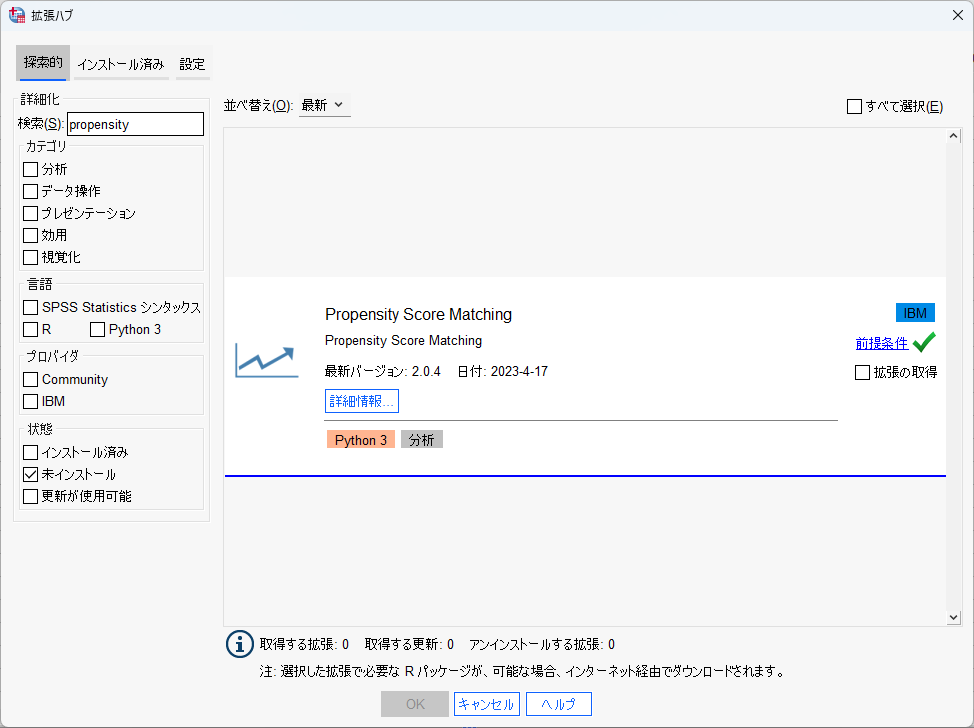
拡張ハブの画面が表示されたら、次の手順で拡張機能を追加します。
(3) 「Propensity Score Matching」の「拡張の取得」にチェックを入れます。
(4) 「OK」ボタンをクリックします。
以上の手順で、「データ」メニューに「Propensity Score Matching」が追加されます。
傾向スコアの推定とマッチング
「Propensity Score Matching」では、傾向スコアによる一致メニューと同じように、傾向スコアの推定とマッチングが同時に行われます。下記の手順は、v29.0.1のスクリーンショットです。
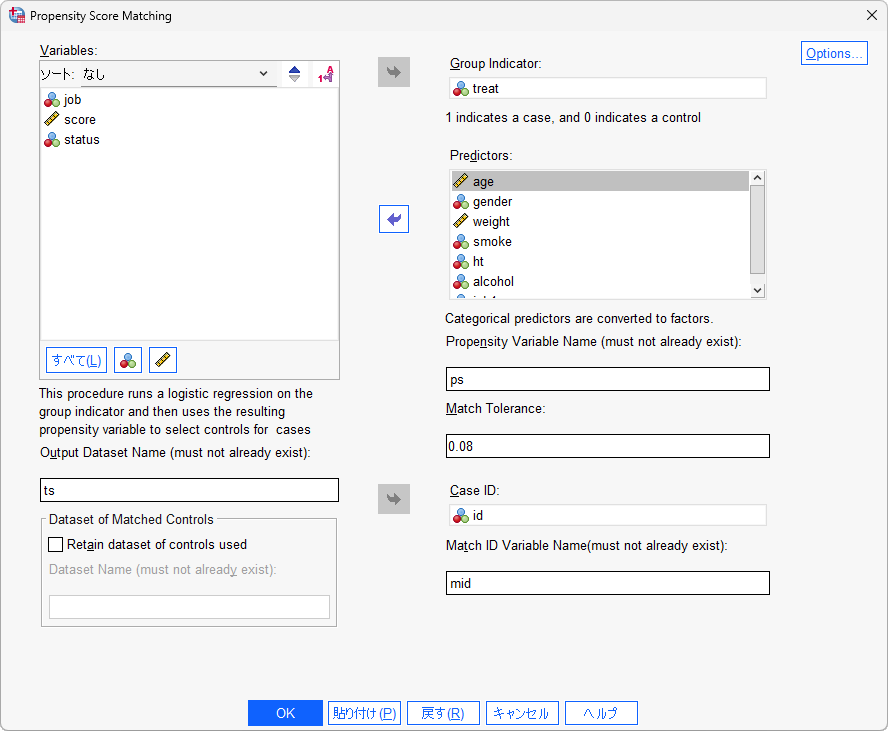
- Group Indicator : 2群への割付を意味する変数を指定します。
- ※数値型(0/1など)である必要があり、文字型(対照群/治療群など)は使用できません。
- Predictors : 2群への割付を説明するための説明変数(交絡因子)を指定します。
- Propensity Variable Name : 保存される傾向スコア変数の任意の名前を入力します。
- Match Tolerance : マッチング対象とするケースの傾向スコアのずれの大きさ(キャリパー)を指定します。この値を大きくするとマッチングされるケースが増え、値を小さくするとマッチングされるケースが減ります。傾向スコアの標準偏差の0.2倍や0.25倍が目安としてよく用いられます。
- Case ID : ケース番号を特定する変数を指定します。
- Match ID Variagble Name : マッチングによって一致したIDを記録するための任意の変数名を入力します。
- Output Dataset Name : マッチング後のデータセットの任意の名前を入力します。
(4)「Random Number Seed」に任意の数値(例えば、123)を入力します。
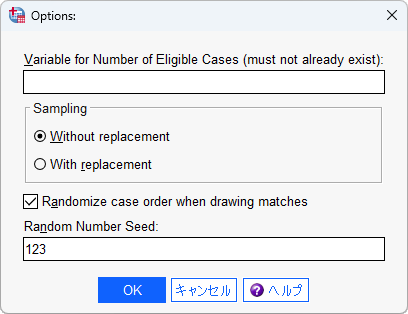
Random Number Seed (乱数のシード) を明示的に指定しておくことで、同一データにおけるマッチング結果の再現を保証できます。シードの指定がない場合、マッチングを行うたびに異なる結果になる可能性があります。シードの値もランダムに決められると良いですが、再現の観点で任意の数値で問題ありません。
(6) 「OK」ボタンをクリックして、傾向スコアの推定とマッチングを実行します。
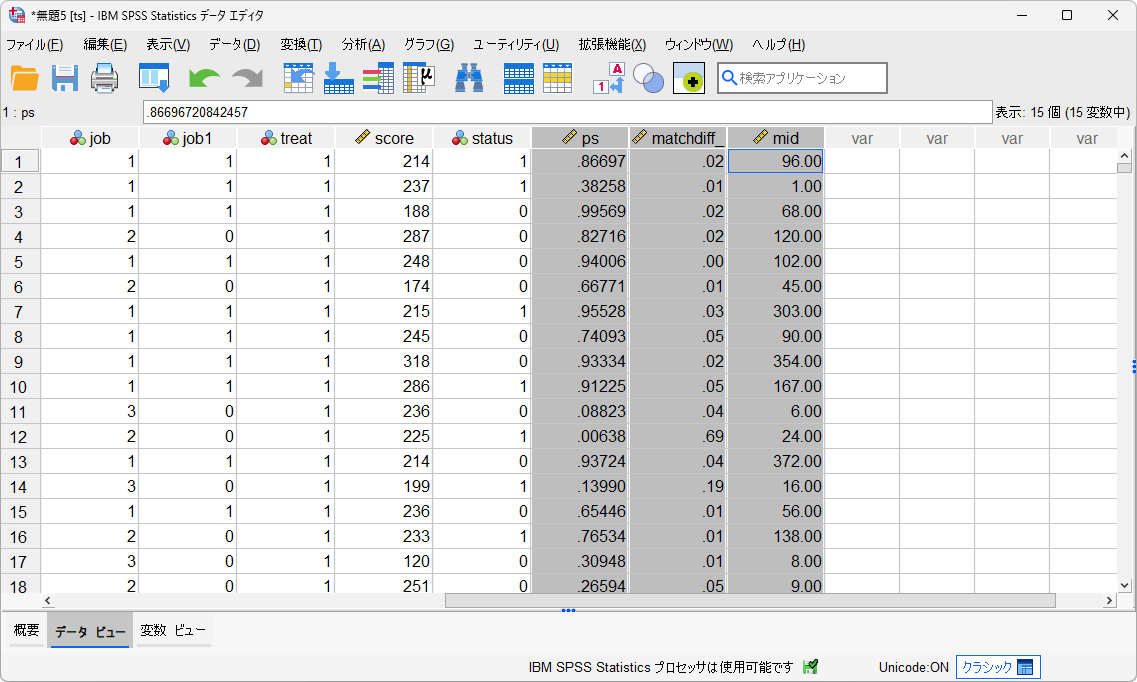
新しいデータセットが作成され、推定された傾向スコアとマッチングIDが追加されます。
上記の例では「ps」が傾向スコアであり介入群に割り付けられる確率を意味します。傾向スコアが近いケースがマッチングされ、「mid」にマッチングされた対象のIDが記録されています。「mid」が欠損値になっているケースは、マッチング対象がなかったケースです。
なお、傾向スコアの推定に必要なRegressionオプションのライセンスが認証されていない場合、以下のエラーメッセージが表示されます。

次にマッチングされたケースのみに絞り込みを行います。
(8) 「IF条件を満たしたケースを含む」を選択して「IF」ボタンをクリックします。
(9) 「MISSING(mid)~=1」と入力します。
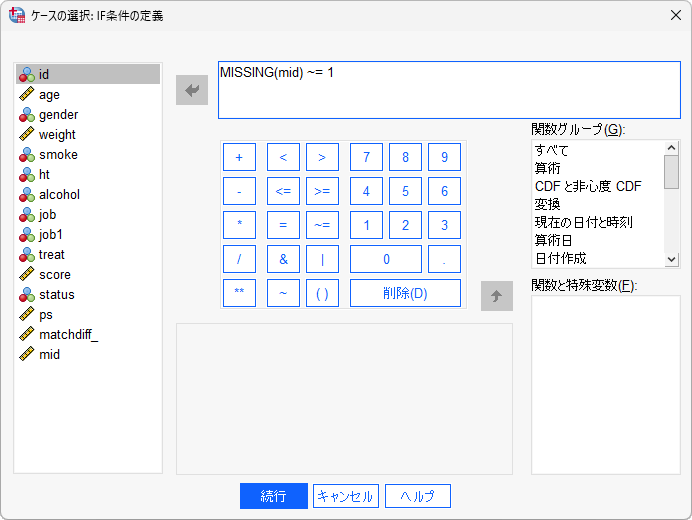
MISSING 関数は、指定した変数に欠損値が含まれるかどうかを判定することができ、欠損値の場合に1または真を返します。MISSING(mid)~=1は、midが欠損値ではないという意味になり、欠損値ではないケースを抽出する場合によく用いられます。
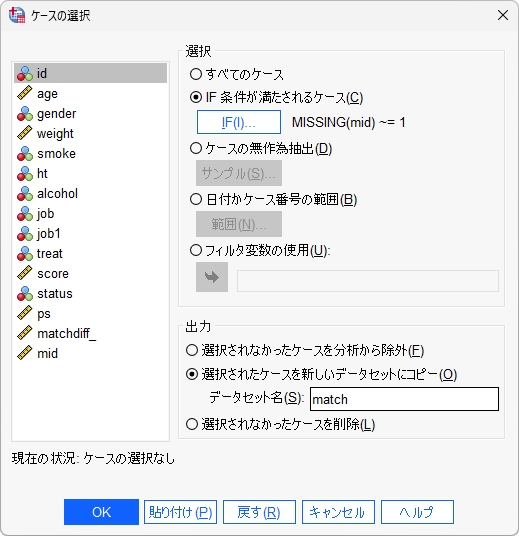
(11) 「選択されたデータを新しいデータセットにコピー」をクリックします。
(12) 「データセット名」に任意のデータセット名を入力します。
(13) 「OK」ボタンをクリックします。
以上の手順でマッチングされたケースのみを含む新たなデータセットが作成されます。このデータセットで記述統計(探索的分析)を実行すると以下のような結果を得ることができます。


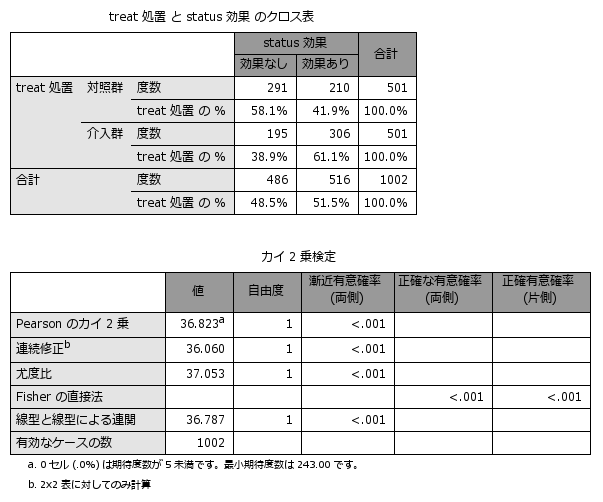
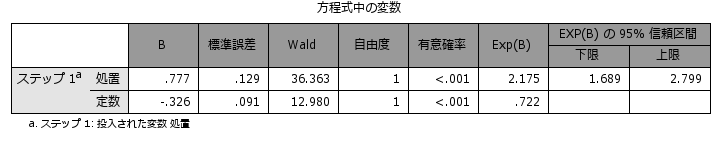

傾向スコアは、共変量を1つにまとめて背景情報のバランス調整に用いることができますが、観察されている共変量で調整を行いますので、観察されていない共変量での調整はできません。また、マッチングを行うと、マッチングできなかったサンプルが分析から除外されることになりますので、最終的に使用できるn数が少なくなります。もともとn数が少ないデータを扱っている場合には、傾向スコアの推定自体ができなかったり、マッチングできるケース数が少なく分析できないなどの問題はありますが、観察型の研究において背景情報のバランシングを行うことで、あたかも無作為割り付けを行ったように単純に分析を行うことができるメリットがあります。
目的や使い方、用途に応じて、IBM SPSS製品を有効にご活用いただき、課題解決・価値創造にお役立てください。
- [1] Rosenbaum, P. R., & Rubin, D. B. (1983). The central role of the propensity score in observational studies for causal effects. Biometrika, 70(1), 41-55.
- [2] Austin, P. C. (2011). An Introduction to Propensity Score Methods for Reducing the Effects of Confounding in Observational Studies. Multivariate Behavioral Research, 46(3), 399-424.
- [3] Shenyang Y. Guo(著),Mark W. Fraser(著)『Propensity Score Analysis: Statistical Methods and Applications』SAGE Publications, Inc(2009)
- [4] 星野崇宏(著)『調査観察データの統計科学 因果推論・選択バイアス・データ融合』岩波書店(2012)
- [5] 新谷歩(著)『今日から使える医療統計』医学書院(2015)
- [6] 中室牧子、津川友介(著)『「原因と結果」の経済学』ダイヤモンド社(2017)