
平均値と標準偏差に基づいてZ得点のフィールドを追加する方法
フィールド作成ノード
この方法は、はじめにグローバルの設定ノードで標準化したい各フィールドの平均値と標準偏差を求めておき、フィールド作成ノードの計算式としてZ得点に変換する式を指定します。グローバルの設定によって各フィールドの平均値や標準偏差などの基本統計量を、グローバル値としてストリームに保持させておくことができ、Modelerの関数を使用して取得することができます。 Z得点は、「(実際の値-平均値)/標準偏差」で求められます。
グローバルの設定ノードの追加と実行
- 1.「出力」パレットの「グローバルの設定」ノードをストリームに追加して開きます
- 2.標準化したいフィールドを指定して「平均」と「標準偏差」のチェックを有効にします
- 3.「実行」ボタンをクリックします
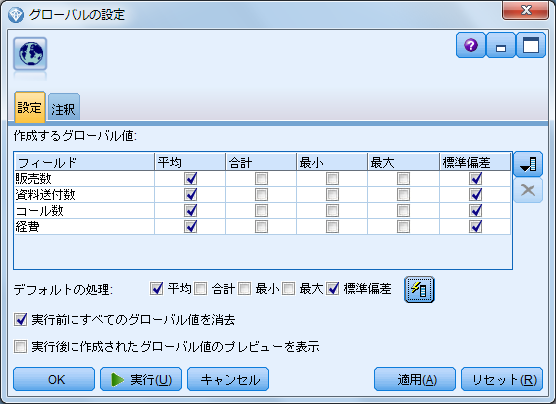
実行した結果は直接テーブルなどに出力されるわけでなく、グローバル値としてストリームに情報が保持されています。そこで、ストリームのプロパティを開いて値を確認します。
グローバル値の確認
- 4.「ツール」メニュー >「ストリームのプロパティ」>「グローバル」を選択します
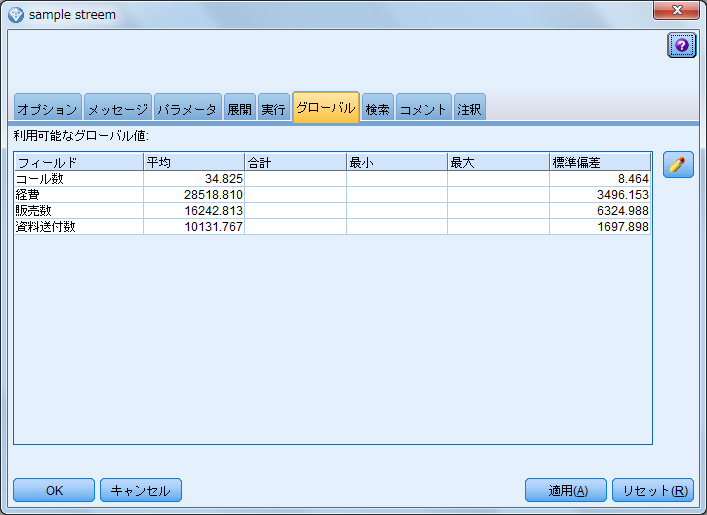
グローバルの設定ノードの計算結果として、各フィールドの「平均」と「標準偏差」がストリームのグローバル値として保持されています。この値をグローバル関数で取得することによって、標準化した新フィールドを作成します。
標準化するフィールドの指定
- 5.「フィールド設定」パレットから「フィールド作成」ノードをストリームに追加します
- 6.「フィールド作成」ノードを開き、「モード」を「複数」に変更します
- 7.「フィールドリスト」に標準化したいフィールドを指定します
- 8.「フィールド名拡張子」に「Z」と入力して、追加方法に「接頭辞」を選択します
- 9.「フィールドのデータ型」を「連続型」に変更します
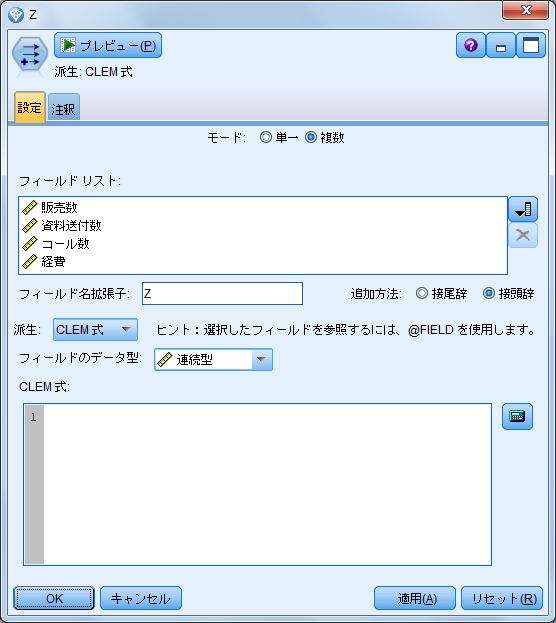
モードを「複数」にすることで、複数のフィールドを対象に同様の計算式を適用することができます。また、「フィールド拡張子」は計算によって新しく作成されるフィールドの名称になり、元のフィールド名に対して指定した「接頭辞」または「接尾辞」が付けられることになります。また、選択された各フィールドを計算式内で指定するためには@FILED関数を用います。 次に、標準化(Z得点)フィールドに変換するための式を入力します。
標準化の計算式の指定-1
- 10.CLEM式ボックスの右横にある「式ビルダーを起動」ボタンをクリックします
- 11.関数の一覧から「@関数」を選択します
- 12.@FIELDをダブルクリックします
- 13.計算パッドから「-」(マイナス)をクリックします
- 14.関数の一覧から「@GLOBAL_MEAN(FIELD)」をダブルクリックします
- 15.関数の一覧から「@FILED」をダブルクリックします
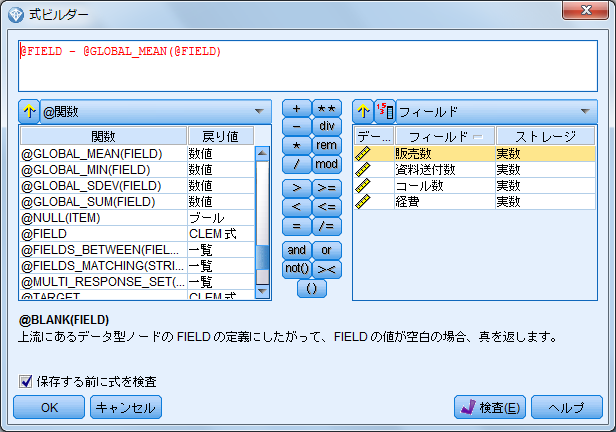
@GLOBAL_MEAN(FIELD)関数は、指定されたフィールドのグローバル平均を取得します。この式によって、指定された各フィールドの値から各フィールドのグローバル平均値がマイナスされます。この結果を各フィールドの標準偏差で割ることによって、Z得点に変換することができます。
標準化の計算式の指定-2
- 16.「@FIELD-@GLOBAL_MEAN(@FILED)」をマウスでドラッグして範囲選択します
- 17.計算パッドから括弧ボタン「()」をクリックします
- 18.計算パッドから「/」(スラッシュ)をクリックします
- 19.関数の一覧から「@GLOBAL_SDEV(FIELD)」をダブルクリックします
- 20.関数の一覧から「@FILED」をダブルクリックします
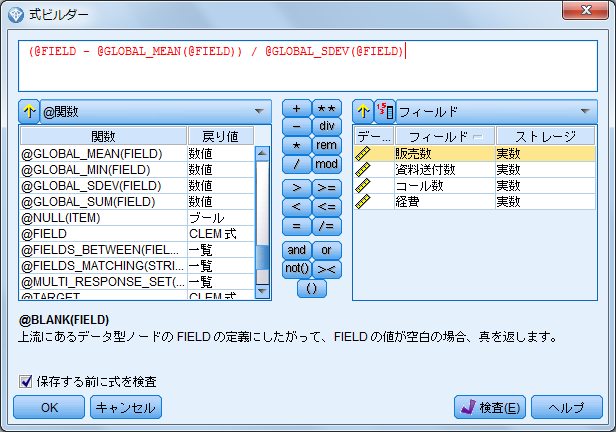
@GLOBAL_SDEV(FILED)関数は、指定されたフィールドのグローバル標準偏差を取得します。以上の式によって、各フィールドについてのZ得点が計算した新規フィールドが作成されます。
設定完了画面
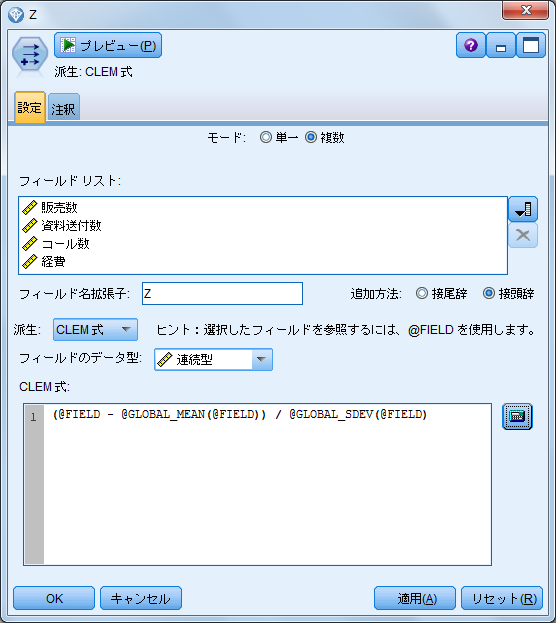
- 21.「OK」ボタンをクリックして「式ビルダー」画面を閉じます
ノードの実行
- 22.「OK」ボタンをクリックしてフィールド作成ノードの画面を閉じます
- 23.「出力」パレットから「テーブル」ノードを追加して実行します
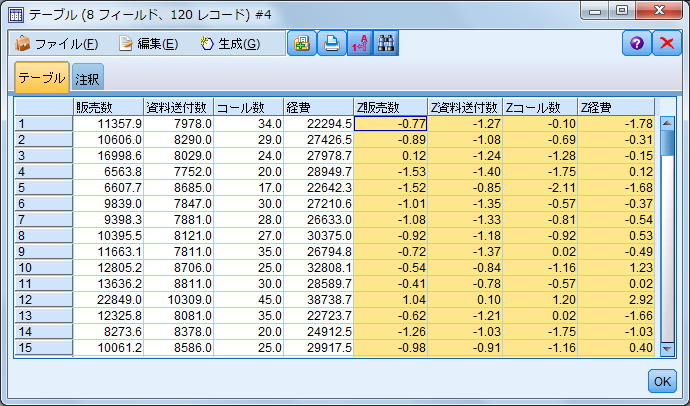
データセットに標準化された新規フィールドが4つ追加されています。これらのフィールドは接頭辞としてZが付いており、それぞれの平均値が0、標準偏差が1の基準に変換されています。
データの自動準備の機能を使用する方法
データの自動準備ノード
この方法は、データの自動準備の機能を利用する方法で、グローバルの設定とフィールド作成ノードを組み合わせる方法よりも簡単です。ただし、標準化以外にも欠損値の補完や日付データの変換などのデータ加工も自動で行われるため、標準化したフィールドの作成のみを目的とする場合は、それ以外の設定をオフにしておく必要があります。
データの自動準備による標準化フィールドの作成
- 1.「フィールド設定」パレットから「データの自動準備」ノードをストリームに追加します
- 2.「データの自動準備」ノードをダブルクリックして編集画面を開きます
- 3.「フィールド」タブを開いて「ユーザー指定の役割を使用」を選択します
- 4.「入力」フィールドに標準化したいフィールドを指定します
- 5.「設定」タブを開きます
- 6.「入力と対象を準備」項目を開きます
- 7.「連続型フィールドを変換」の「共通スケールにすべての連続型入力フィールドを投入する」を有効にしておきます
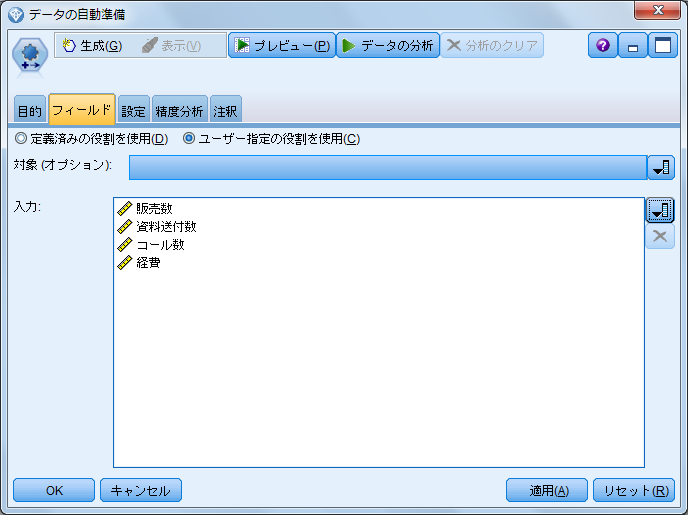
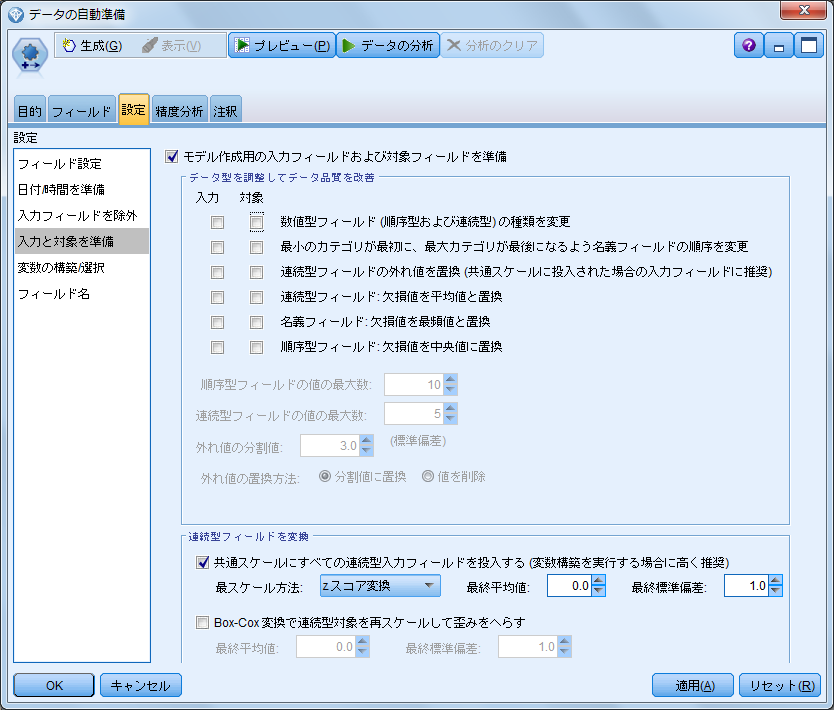
結果の確認
- 8.「OK」ボタンをクリックします
- 9.「出力」パレットから「テーブル」ノードを追加して実行します
Z得点に変換された新フィールドが確認できます。これらのフィールドの平均値は0、標準偏差は1に変換されています。また、標準化されたフィールドを既存のフィールドと同じデータセットに統合する場合は、レコード設定パレットのレコード結合ノードを利用して結合を行います。