K-eansのクラスター数の指定
自動クラスタリングノード
IBM SPSS ModelerのK-Meansノードで一度に指定できるクラスター数は1パターンだけで、デフォルトでは5個です。複数パターンのクラスター数で実行したい場合は、自動クラスタリングノードを用いると効率的です。
ノードの追加
- 1.ストリームに「自動クラスタリング」ノードを追加します
- 2.エキスパートタブで「K-means」の「モデルパラメータ」をクリックします
- 3.「指定…」を選択します
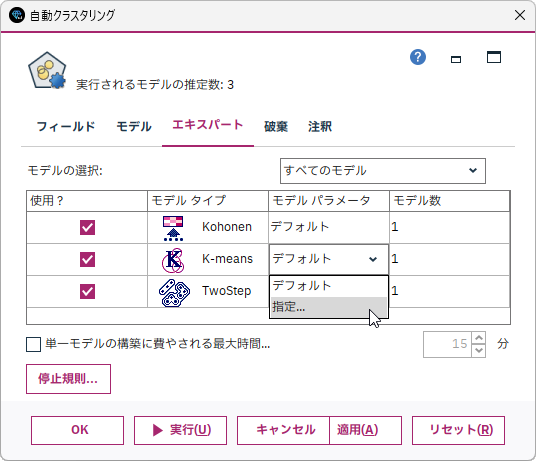
次に、クラスター数の設定を変更します。
パラメータ設定
- 4.「クラスター数」の「オプション」を選択します
- 5.「指定」を選択します
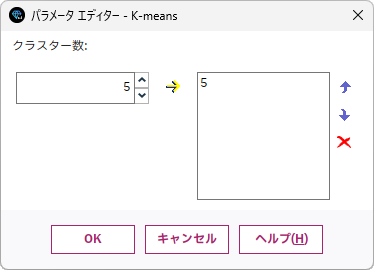
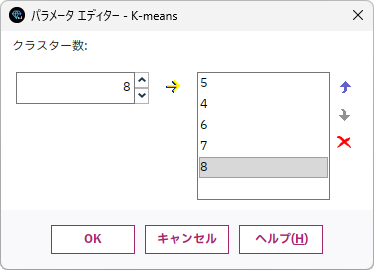
クラスター数を指定するエディターが表示されるので、試行したいクラスターの数を指定します。クラスター数として「4」「6」「7」「8」を追加してみます。
複数パターンのクラスター数の指定
- 6.「クラスター数」に「4」を指定して、追加(→)ボタンをクリックします
- 7.「クラスター数」に「6」を指定して、追加(→)ボタンをクリックします
- 8.「クラスター数」に「7」を指定して、追加(→)ボタンをクリックします
- 9.「クラスター数」に「8」を指定して、追加(→)ボタンをクリックします
- 10.「OK」ボタンをクリックします
以上の設定で、クラスター数4~8個でそれぞれ分析を実行することになります。
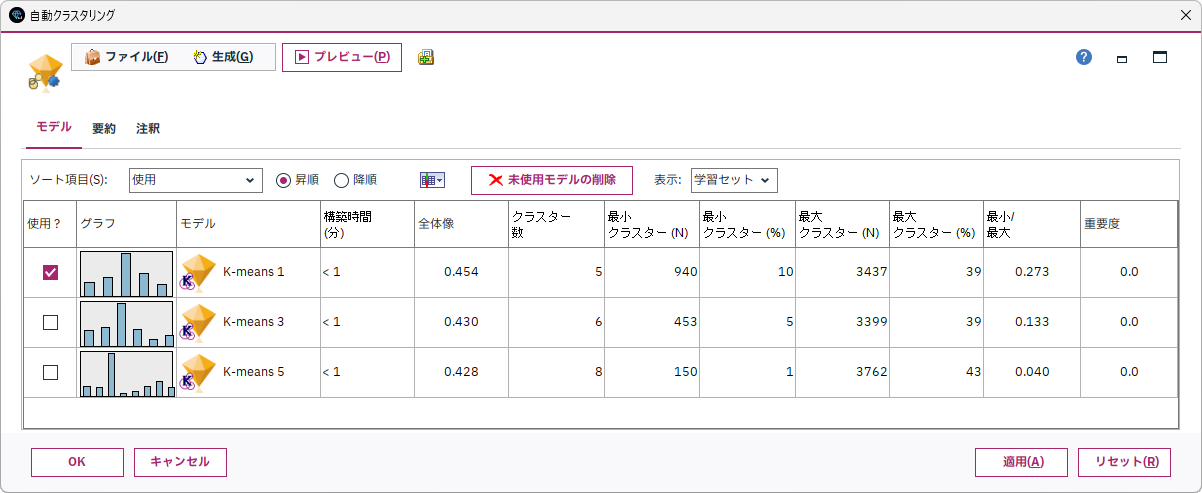
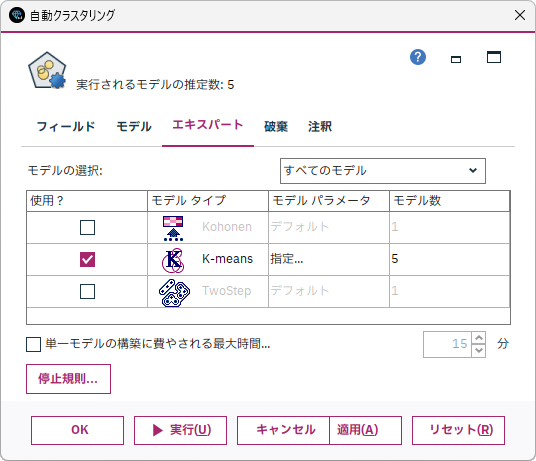
この設定でK-meansによって作成されるモデル数は全部で5個になります。この例では、KohonenとTwo-Stepのモデルタイプはオフにしています。デフォルトでは、結果について良いと判断されるものから上位3個が選択されます(この設定はモデルタブの「保存するモデル数」で変更可能です)。
モデル作成の結果、全体像(レコードが所属するクラスター中心への距離と最近隣クラスター中心との距離の情報に基づいて計算されるシルエット)と呼ばれる指標に基づき、クラスター数5個の場合がレコードをもっとも明確に分類できることが分かりました。試行したクラスター数の中で2番目に良いのは6個の場合、3番目に良いのは8個に分類する場合のようです。